

Background
Though many datasets contain sensitive, private information, they are nevertheless often released due to the benefits they can provide to researchers and the general public. For example, medical datasets are published to allow researchers to develop improved data-driven medical diagnosis techniques. Due to the sensitive information they contain (e.g. medical records), these datasets should be sufficiently anonymised before release – ensuring that no persons contained within the dataset are harmed by the release.
Data de-identification is often the default technique for anonymising data. This approach consists of removing any obvious “personally identifiable information” (Pii) from the dataset. For example, names, addresses, and date-of-births are often obscured. However, recent privacy attacks and advancements in privacy-preserving research have revealed that datasets anonymised via de-identification can be often compromised via “linkage attacks”. In a linkage attack the published data is de-anonymised by linking it to auxiliary information obtained from another source. A famous example is the Netflix/IMDB linkage attack [1, 2], where persons in an anonymised database of Netflix movie ratings were re-identified by linking the Netflix data to IMBD.
In this challenge, you are provided a set of sensitive datasets that have been anonymised via de-identification before publication. You will investigate whether this de-identification is robust to privacy attacks. Your goal is to de-anonymise the sensitive data by linking it back to some Pii data, thus revealing the private information of individuals in the Pii dataset and exposing any flaws in the process used to anonymise the sensitive data. The team that successfully de-anonymises the most data wins!
This challenge will demonstrate the limitations of data de-identification methods and thus promote an appreciation of the utility of more sophisticated Privacy Enhancing Technologies (PETs), such as differential privacy (for more details on differential privacy, see Challenge 1). It is also an excellent opportunity for participants to practice and improve upon their Python data manipulation and data analysis skills.
Requirements
Teams will require a minimum of 1 person with some technical knowledge of manipulating data and analysing data with python and pandas. We would encourage a minimum of 2 per team, in the spirit of collaboration.
Each team must have a laptop with an internet connection to compete in the challenge. The challenge can be performed online via Google Colab (so no software need to be installed in advance). To run on Colab at least one member of the team will need a Google account.
Technical task: Credit card transactions linkage attack
Overview
Bank X are believers in open data and often publicly releases anonymised datasets. Recently, the bank has been plagued with credit card fraud issues. As such, they have released a credit-card transactions dataset (containing the transaction activity of their California-based customers in 2019) where each transaction is labelled as fraudulent or non-fraudulent. They hope researchers will use the data to develop improved techniques for detecting credit-card fraud. The bank asserts that the data-set has been fully anonymised, as it does not contain personally identifiable information such as customer names, date-of-births, or home addresses.
As privacy-preserving machine learning experts, you are sceptical of the bank’s data privacy policies. You contact them regarding your concerns and they offer you a bounty if you can prove that the data they have released is vulnerable to an attack.
Data
You have access to four of the banks’ datasets:
- CreditCardTransactions.csv: This is the public, anonymized credit-card transaction data the bank has recently released.
- FicoCreditScore.csv: This is a public, anonymised dataset aimed at investigating the correlations between the home address and credit risk.
- CreditCardData.csv: This is a public, anonymised dataset describing customer credit card churn.
- PersonalIdentifiableInfo.csv: The bank has provided you with this data in anticipation that a data breach may occur at some point in the future, to aid your investigation.
Goal
Your goal is to de-anonymise the publicly released datasets. This should be achieved by linking the data back to the persons contained in PersonalIdentifiableInfo.csv, thus revealing their private information and exposing any flaws in the bank’s data privacy policies.
Starter Code
To help you get up and running, we provide a starter Jupyter notebook (getting_started.ipynb) to load the data and install some recommended libraries. It also provides more details about the datasets and gives an introduction to implementing linkage attacks. It is recommended to run this notebook online via Colab (but it may also be run locally).
Instructions for running online on Colab:
- Open getting_started.ipynb
- Click “Changes will not be saved”:
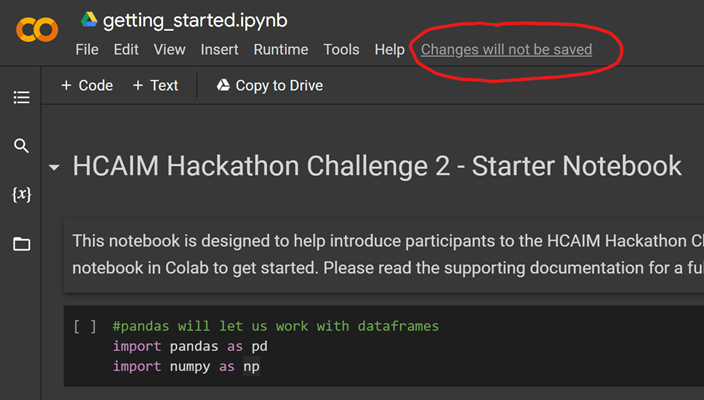
- Click “Save a copy in drive”:
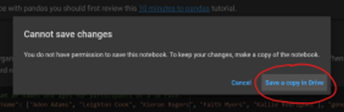
- Change to the “Copy of getting_started.ipynb” notebook
- Begin running the notebook!
Evaluation
You will receive a score based on an automated quantitative assessment of your linkage attack. The more data you successfully de-anonymise, the higher your score will be. More details on the submission and evaluation process can be found at the bottom of the starter notebook. A top-3 leaderboard will be displayed in the Challenge 2 slack channel.
Reading Materials
- This blog post on Oblivious’ site gives a nice introduction to attacks on privacy.
- The programming differential privacy guide is helpful for the implementation of differentially private mechanisms. The De-identification notebook is particularly relevant to this challenge.
- The PPML playlist created by CeADAR gives a high-level outline of how privacy-preserving techniques can be applied to data.
- For a deeper dive into differential privacy and privacy attacks, see Section 1 of The Algorithmic Foundations of Differential Privacy, and Section 1 of Exposed! A Survey of Attacks on Private Data.
- You should brush up on your python and pandas skills before the challenge. See the 10 minutes to pandas tutorial if you have little prior pandas experience. For an introduction to linkage attacks in python see this toy_linkage_attack.ipynb notebook that was provided ahead of the challenge.