
Información administrativa
| Título | Propagación a plazo |
| Duración | 60 |
| Módulo | B |
| Tipo de lección | Conferencia |
| Enfoque | Técnico — Aprendizaje profundo |
| Tema | Pase hacia delante |
Keywords
Pase hacia adelante, Pérdida,
Objetivos de aprendizaje
- Entender el proceso de un pase hacia adelante
- Entender cómo calcular una predicción de pase hacia adelante, así como la pérdida desenchufada
- Desarrollar un pase delantero sin módulos en Python (que no sea Numpy)
- Desarrollar un pase hacia adelante usando Keras
Preparación prevista
Eventos de aprendizaje que se completarán antes
Ninguno.
Obligatorio para los estudiantes
Ninguno.
Opcional para estudiantes
- Multiplicación de matrices
- Empezar con Numpy
- Conocimiento de la regresión lineal y logística (del Período A Machine Learning: Conferencia: Regresión lineal, GLRs, GADs)
Referencias y antecedentes para estudiantes
- John D Kelleher y Brain McNamee. (2018), Fundamentos del aprendizaje automático para análisis de datos predictivos, MIT Press.
- Michael Nielsen. (2015), Redes neuronales y aprendizaje profundo, 1. Prensa de determinación, San Francisco CA USA.
- Charu C. Aggarwal. (2018), Redes neuronales y aprendizaje profundo, 1. Springer
- Antonio Gulli, Sujit Pal. Aprendizaje profundo con Keras, Packt, [ISBN: 9781787128422].
Recomendado para profesores
Ninguno.
Material didáctico
Instrucciones para profesores
Esta conferencia presentará a los estudiantes los fundamentos de la propagación hacia adelante para una red neuronal artificial. Esto introducirá a los estudiantes a la topología (pesos, sinapsis, funciones de activación y funciones de pérdida). Los estudiantes podrán hacer un pase hacia adelante usando lápiz y papel, usando Python con solo la biblioteca Numpy (para la manipulación de matrices) y luego usando KERAS como parte del tutorial asociado con este LE. Esto generará una comprensión fundamental de qué funciones de activación se aplican a contextos de problemas específicos y cómo las funciones de activación difieren en la complejidad computacional. En la conferencia se examinará la función de activación de la capa externa y las correspondientes funciones de pérdida para casos de uso tales como clasificación binomial, regresión y clasificación multiclase.
- Visión general de una red neuronal
- Definición de términos/componentes
- Pesos y funciones de activación
- Funciones de pérdida, cuál para qué contexto problema
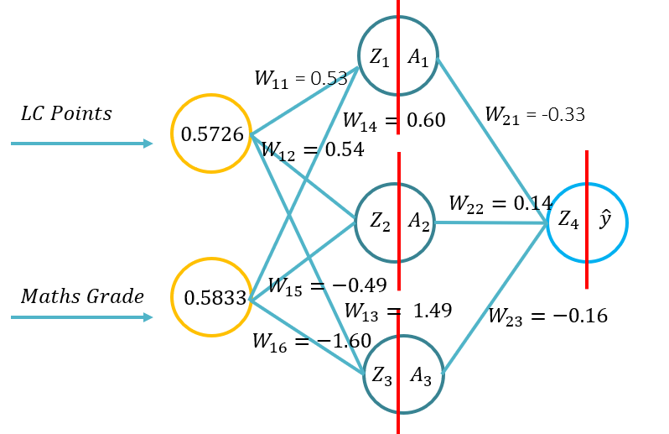
- Uso de matrices para realizar un pase hacia adelante
Nota:
- Uso de Sigmoid en la capa exterior y MSE como la función de pérdida.
- Con limitaciones de tinos, se seleccionó un contexto singular de enfoque/topología/problema. Típicamente, uno comenzaría con la regresión para un pase hacia adelante (con MSE como la función de pérdida), y para derivar la retropropagación (por lo tanto, teniendo una función de activación lineal en la capa de salida, donde esto reduce la complejidad de la derivación de la función de retropropagación), entonces uno se movería típicamente a una función de clasificación binaria, con sigmoide en la capa de salida, y una función binaria de pérdida de entropía cruzada. Con limitaciones de tiempo, este conjunto de conferencias usará tres funciones de activación ocultas de ejemplo diferentes, pero usará un contexto de problema de regresión. Para agregar la complejidad de una función de activación sigmoide en la capa de salida, el problema de regresión utilizado en las dos primeras conferencias de este conjunto, el ejemplo del problema se basa en un valor objetivo normalizado (0-1 basado en un problema de grado porcentual 0-100 %), por lo que sigmoid se utiliza como una función de activación en la capa de salida. Este enfoque permite a los estudiantes migrar fácilmente entre los problemas de regresión y clasificación binaria, simplemente cambiando la función de pérdida si un problema de clasificación binaria, o si se está utilizando un problema de regresión no normalizado, el estudiante simplemente elimina la función de activación de la capa externa.
- Los componentes principales son la aplicación de, utilizando una biblioteca de alto nivel, en este caso KERAS a través de la biblioteca TensorFlow 2.X.
- El lápiz y el papel son opcionales y solo se utilizan para mostrar la derivación y aplicación de pase y propagación hacia adelante (utilizando los ejemplos de las diapositivas de la conferencia).
- El código Python sin el uso de bibliotecas de alto nivel, se utiliza para mostrar cuán simple es una red neuronal (usando los ejemplos de las diapositivas de conferencias). Esto también permite la discusión sobre la rápida multiplicación numérica/mátricas e introduce por qué usamos GPUs/TPU como un elemento opcional.
- Keras y TensorFlow 2.X se utilizan y se utilizarán para todos los ejemplos futuros.
Esquema
| Duración (Min) | Descripción |
|---|---|
| 10 | Definición de Componentes de Red Neural |
| 15 | Pesos y funciones de activación (Sigmoid, TanH y ReLu) |
| 15 | Funciones de pérdida (regresión, clasificación binomial y activación multiclase) |
| 15 | Uso de matrices para un pase delantero |
| 5 | Recapitulación en el pase delantero |
Reconocimientos
El programa de maestría en IA centrada en el ser humano fue cofinanciado por el Mecanismo «Conectar Europa» de la Unión Europea en virtud de la subvención «CEF-TC-2020-1 Digital Skills 2020-EU-IA-0068».