
Informations administratives
| Titre | Propagation vers l’avant |
| Durée | 60 |
| Module | B |
| Type de leçon | Conférence |
| Focus | Technique — Deep Learning |
| Sujet | Laissez-passer vers l’avant |
Mots-clés
Passe avant, perte,
Objectifs d’apprentissage
- Comprendre le processus d’une passe avant
- Comprendre comment calculer une prédiction de passe avant, ainsi que la perte débranchée
- Développer un pass vers l’avant en n’utilisant aucun module en Python (autre que Numpy)
- Développer une passe avant en utilisant Keras
Préparation prévue
Événements d’apprentissage à compléter avant
Aucun.
Obligatoire pour les étudiants
Aucun.
Optionnel pour les étudiants
- Multiplication des matrices
- Commencer avec Numpy
- Connaissance de la régression linéaire et logistique (à partir de la période A Machine Learning: Conférence: Régression linéaire, GLR, GAD)
Références et antécédents pour les étudiants
- John D Kelleher et Brain McNamee. (2018), Fondamentals of Machine Learning for Predictive Data Analytics, MIT Press.
- Michael Nielsen. (2015), Réseaux neuronaux et apprentissage profond, 1. Presse de détermination, San Francisco CA USA.
- Charu C. Aggarwal. (2018), Réseaux neuronaux et apprentissage profond, 1. Springer
- Antonio Gulli, Sujit Pal. Apprentissage profond avec Keras, Packt, [ISBN: 9781787128422].
Recommandé pour les enseignants
Aucun.
Matériel de leçon
Instructions pour les enseignants
Cette conférence introduira aux étudiants les fondamentaux de la propagation vers l’avant pour un réseau de neurones artificiels. Cela introduira les étudiants à la topologie (poids, synapses, fonctions d’activation et fonctions de perte). Les étudiants seront alors en mesure de faire un pass vers l’avant en utilisant le stylo et le papier, en utilisant Python avec seulement la bibliothèque Numpy (pour la manipulation des matrices) puis en utilisant KERAS dans le cadre du tutoriel associé à ce LE. Cela permettra de comprendre fondamentalement quelles fonctions d’activation s’appliquent à des contextes de problèmes spécifiques et comment les fonctions d’activation diffèrent en termes de complexité informatique. Dans la conférence, la fonction d’activation de la couche externe et les fonctions de perte correspondantes seront examinées pour des cas d’utilisation tels que la classification binomiale, la régression et la classification multiclasse.
- Vue d’ensemble d’un réseau neuronal
- Définition des termes/composants
- Poids et fonctions d’activation
- Fonctions de perte, lesquelles pour lesquelles le contexte du problème
- Utiliser des matrices pour effectuer une passe avant
Note:
- Utilisation de Sigmoid dans la couche externe et MSE comme fonction de perte.
- Avec des limites, une approche/topologie/contexte singulier a été sélectionnée. Typiquement, on commencerait par une régression pour une passe avant (avec MSE comme fonction de perte), et pour dériver la rétropropagation (ayant ainsi une fonction d’activation linéaire dans la couche de sortie, où cela réduit la complexité de la dérivation de la fonction de rétropropagation), puis on passerait généralement à une fonction de classification binaire, avec sigmoïde dans la couche de sortie, et une fonction binaire de perte d’entropie croisée. Avec des contraintes de temps, cet ensemble de conférences utilisera trois fonctions d’activation cachées, mais utilisera un contexte de problème de régression. Pour ajouter la complexité d’une fonction d’activation sigmoïde dans la couche de sortie, le problème de régression utilisé dans les deux premières conférences de cet ensemble, l’exemple de problème est basé sur une valeur cible normalisée (0-1 basée sur un pourcentage de problème de grade 0-100 %), donc sigmoïde est utilisé comme une fonction d’activation dans la couche de sortie. Cette approche permet aux étudiants de migrer facilement entre les problèmes de régression et de classification binaire, en changeant simplement la fonction de perte si un problème de classification binaire, ou si un problème de régression non normalisé est utilisé, l’étudiant supprime simplement la fonction d’activation de la couche externe.
- Les composants de base sont l’application, à l’aide d’une bibliothèque de haut niveau, dans ce cas KERAS via la bibliothèque TensorFlow 2.X.
- Le stylo et le papier sont facultatifs et ne sont utilisés que pour montrer la dérivation et l’application de la passe avant et de la rétropropagation (en utilisant les exemples des diapositives de conférence).
- Le code Python sans l’utilisation de bibliothèques de haut niveau, est utilisé pour montrer à quel point un réseau neuronal simple (en utilisant les exemples des diapositives de conférence). Cela permet également de discuter de la multiplication numérique/matrices rapide et d’introduire pourquoi nous utilisons les GPU/TPU comme élément optionnel.
- Keras et TensorFlow 2.X sont utilisés et seront utilisés pour tous les exemples futurs.
Esquisse
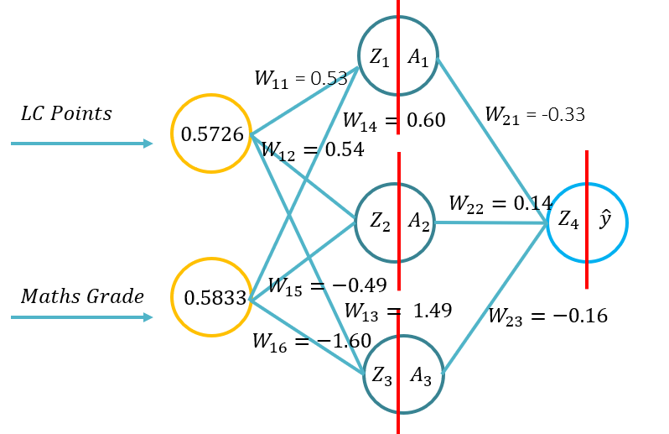
| Durée (min) | Description |
|---|---|
| 10 | Définition des composantes du réseau neuronal |
| 15 | Poids et fonctions d’activation (Sigmoid, TanH et ReLu) |
| 15 | Fonctions de perte (régression, classification binomiale et activation multiclasse) |
| 15 | Utilisation de matrices pour une passe avant |
| 5 | Récapitulation sur la passe avant |
Remerciements
Le programme de master IA centré sur l’humain a été cofinancé par le mécanisme pour l’interconnexion en Europe de l’Union européenne dans le cadre de la subvention CEF-TC-2020-1 Digital Skills 2020-EU-IA-0068.