
Административна информация
| Дял | Разпространение напред |
| Продължителност | 60 |
| Модул | Б |
| Вид на урока | Лекция |
| Фокус | Технически — задълбочено обучение |
| Тема | Напред пас |
Ключови думи
Напред пас, загуба,
Учебни цели
- Разбиране на процеса на напред пас
- Разберете как да изчислите прогноза за напред пас, както и загуба без включване
- Разработване на напред пас, като не се използват модули в Python (различни от Numpy)
- Разработване на напред пас с помощта на Keras
Очаквана подготовка
Обучение на събития, които трябва да бъдат завършени преди
Няма.
Задължително за студентите
Няма.
Незадължително за студенти
- Умножение на матрици
- Да започнем с Numpy
- Познаване на линейната и логистична регресия (от Период А Машино Учебно Учене: Лекция: Линейна регресия, GLR, GADs)
Референции и фон за студенти
- Джон Келър и Мозък Макнами. (2018 г.), Fundamentals of Machine Learning for Predictive Data Analytics, MIT Press.
- Майкъл Нилсън. (2015 г.), „Неврални мрежи и задълбочено обучение“, 1. Преса за решителност, Сан Франциско, САЩ.
- Чару С. Агарвал. (2018 г.), невронни мрежи и задълбочено обучение, 1. Спрингър
- Антонио Гули, Суджит Пал. Дълбоко обучение с Keras, Packt, [ISBN: 9781787128422].
Препоръчва се за учители
Няма.
Материали за уроци
Инструкции за учители
Тази лекция ще запознае студентите с основите на разпространението напред за изкуствена невронна мрежа. Това ще запознае студентите с топологията (тегло, синапси, функции за активиране и функции за загуба). След това студентите ще могат да направят напред пас с помощта на писалка и хартия, като използват Python само с библиотеката Numpy (за матрици матрици) и след това използват KERAS като част от урока, свързан с този LE. Това ще изгради фундаментално разбиране за това какви функции за активиране се прилагат за конкретни проблемни контексти и как функциите за активиране се различават по изчислителна сложност. В лекцията функцията за активиране на външния слой и съответните функции за загуба ще бъдат разгледани за случаи на употреба като биномна класификация, регресия и многокласова класификация.
- Преглед на невронната мрежа
- Определение на термини/компоненти
- Тегла и функции за активиране
- Функции за загуба, за които има проблемен контекст
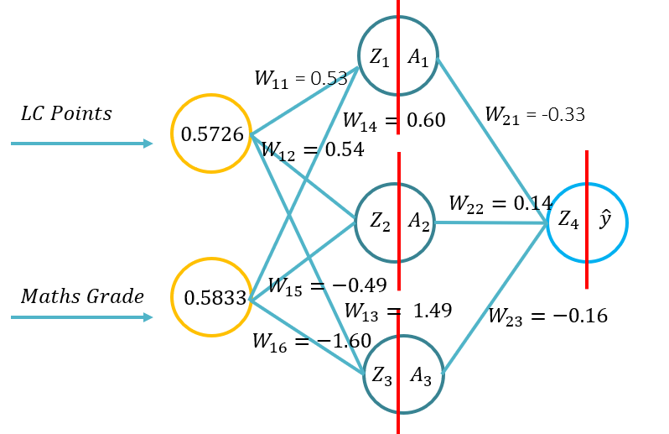
- Използване на матрици за извършване на напред пас
Бележка:
- Използване на Sigmoid във външния слой и MSE като функция за загуба.
- С ограниченията на Tine беше избран единствен подход/топология/проблемен контекст. Обикновено човек започва с регресия за напред (с MSE като функция за загуба) и за извличане на обратно размножаване (като по този начин има линейна активационна функция в изходния слой, където това намалява сложността на извличането на функцията за обратно размножаване), След това обикновено се преминава към бинарна функция за класификация, със сигмоид в изходния слой и бинарна функция за загуба на ентропия. С ограничения във времето този набор от лекции ще използва три различни примерни скрити функции за активиране, но ще използва контекст на регресионен проблем. За да се добави сложността на функцията за сигмоидно активиране в изходния слой, проблемът с регресията, използван в първите две лекции от този набор, примерът на проблема се основава на нормализирана целева стойност (0—1 въз основа на проблем с процентна оценка 0—100 %), като по този начин сигмоидът се използва като функция за активиране в изходния слой. Този подход позволява на учениците лесно да мигрират между проблеми с регресията и двоичната класификация, като просто променят функцията за загуба, ако проблемът с двоичната класификация или ако се използва ненормализиран проблем с регресията, студентът просто премахва функцията за активиране на външния слой.
- Основните компоненти са приложението на, използвайки библиотека на високо ниво, в този случай KERAS чрез библиотеката TensorFlow 2.X.
- Писалката и хартията са незадължителни и се използват само за показване на изхода и приложението за напред и обратно размножаване (като се използват примерите от слайдовете на лекцията).
- Python код без използване на библиотеки от високо ниво, се използва, за да покаже колко проста невронна мрежа (използвайки примерите от лекция слайдове). Това също така дава възможност за обсъждане на бързото умножение на матрици/матрици и да се въведе защо използваме графични процесори/TPUs като незадължителен елемент.
- Keras и TensorFlow 2.X се използват и ще бъдат използвани за всички бъдещи примери.
Очертаване
| Продължителност (минимум) | Описание |
|---|---|
| 10 | Дефиниране на компонентите на невронната мрежа |
| 15 | Тегла и функции за активиране (сигмоидни, TanH и ReLu) |
| 15 | Функции за загуба (регресия, биномна класификация и активиране на няколко класа) |
| 15 | Използване на матрици за напред пас |
| 5 | Recap на напред пас |
Потвърждения
Магистърската програма по ИИ, насочена към човека, беше съфинансирана от Механизма за свързване на Европа на Европейския съюз под формата на безвъзмездни средства № CEF-TC-2020—1 Digital Skills 2020-EU-IA-0068.