
Información administrativa
| Título | Tutorial: Fundamental del aprendizaje profundo |
| Duración | 180 min (60 min por tutorial) |
| Módulo | B |
| Tipo de lección | Tutorial |
| Enfoque | Técnico — Aprendizaje profundo |
| Tema | Avance y retropropagación |
Keywords
propagación hacia adelante, retropropagación, sintonización de hiperparámetros,
Objetivos de aprendizaje
- el estudiante entiende el concepto de propagación hacia adelante
- el estudiante obtiene una vista sobre cómo derivar la retropropagación
- el estudiante puede aplicar la retropropagación
- el estudiante aprende la forma de sintonizar hiperparámetros
Preparación prevista
Eventos de aprendizaje que se completarán antes
Obligatorio para los estudiantes
- John D Kelleher y Brain McNamee. (2018), Fundamentos del aprendizaje automático para análisis de datos predictivos, MIT Press.
- Michael Nielsen. (2015), Redes neuronales y aprendizaje profundo, 1. Prensa de determinación, San Francisco CA USA.
- Charu C. Aggarwal. (2018), Redes neuronales y aprendizaje profundo, 1. Springer
- Antonio Gulli, Sujit Pal. Aprendizaje profundo con Keras, Packt, [ISBN: 9781787128422].
Opcional para estudiantes
- Multiplicación de matrices
- Empezar con Numpy
- Conocimiento de la regresión lineal y logística
Referencias y antecedentes para estudiantes
Ninguno.
Recomendado para profesores
Ninguno.
Material didáctico
Ninguno.
Instrucciones para profesores
Este Evento de Aprendizaje consta de tres conjuntos de tutoriales que cubren temas fundamentales de aprendizaje profundo. Esta serie de tutoriales consiste en proporcionar una visión general de un pase hacia adelante, la derivación de la retropropagación y el uso de código para proporcionar una visión general para los estudiantes sobre lo que hace cada parámetro y cómo puede afectar el aprendizaje y la convergencia de una red neuronal:
- Propagación a plazo: Ejemplos de lápiz y papel, y ejemplos de pitón usando Numpy (para fundamentos) y Keras mostrando un módulo de alto nivel (que utiliza Tensorflow 2.X).
- Derivación y aplicación de la retropropagación: Ejemplos de lápiz y papel, y ejemplos de pitón usando Numpy (para fundamentos) y Keras mostrando un módulo de alto nivel (que utiliza Tensorflow 2.X).
- Sintonización de hiperparámetros: Ejemplos de Keras que destacan gráficos de diagnóstico ejemplares basados en los efectos para cambiar hiperparámetros específicos (usando un conjunto de datos de ejemplo HCAIM conjuntos de datos para la enseñanza de IA ética (Census Dataset).
Notas para la entrega (según conferencias)
- Uso de Sigmoid en la capa exterior y MSE como la función de pérdida.
- Con limitaciones de tinos, se seleccionó un contexto singular de enfoque/topología/problema. Típicamente, uno comenzaría con la regresión para un pase hacia adelante (con MSE como la función de pérdida), y para derivar la retropropagación (por lo tanto, teniendo una función de activación lineal en la capa de salida, donde esto reduce la complejidad de la derivación de la función de retropropagación), entonces uno se movería típicamente a una función de clasificación binaria, con sigmoide en la capa de salida, y una función binaria de pérdida de entropía cruzada. Con limitaciones de tiempo, este conjunto de conferencias usará tres funciones de activación ocultas de ejemplo diferentes, pero usará un contexto de problema de regresión. Para agregar la complejidad de una función de activación sigmoide en la capa de salida, el problema de regresión utilizado en las dos primeras conferencias de este conjunto, el ejemplo del problema se basa en un valor objetivo normalizado (0-1 basado en un problema de grado porcentual 0-100 %), por lo que sigmoid se utiliza como una función de activación en la capa de salida. Este enfoque permite a los estudiantes migrar fácilmente entre los problemas de regresión y clasificación binaria, simplemente cambiando la función de pérdida si un problema de clasificación binaria, o si se está utilizando un problema de regresión no normalizado, el estudiante simplemente elimina la función de activación de la capa externa.
- Los componentes principales son la aplicación de, utilizando una biblioteca de alto nivel, en este caso KERAS a través de la biblioteca TensorFlow 2.X.
- El lápiz y el papel son opcionales y solo se utilizan para mostrar la derivación y aplicación de pase y propagación hacia adelante (utilizando los ejemplos de las diapositivas de la conferencia).
- El código Python sin el uso de bibliotecas de alto nivel, se utiliza para mostrar cuán simple es una red neuronal (usando los ejemplos de las diapositivas de conferencias). Esto también permite la discusión sobre la rápida multiplicación numérica/mátricas e introduce por qué usamos GPUs/TPU como un elemento opcional.
- Keras y TensorFlow 2.X se utilizan y se utilizarán para todos los ejemplos futuros.
Tutorial 1 — Proliferación a futuro
Instrucciones del profesor
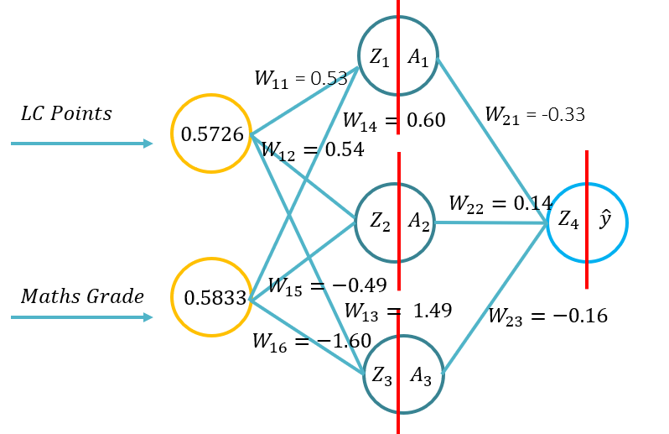
- Este tutorial presentará a los estudiantes los fundamentos de la propagación hacia adelante para una red neuronal artificial. Este tutorial consistirá en un pase hacia adelante usando lápiz y papel, usando Python con solo la biblioteca Numpy (para la manipulación de matrices) y luego usando KERAS.. Esto se basará en la comprensión fundamental de qué funciones de activación se aplican a contextos de problemas específicos y cómo las funciones de activación difieren en la complejidad computacional y la aplicación desde lápiz y papel, para codificar desde cero usando Numpy y luego utilizando un módulo de alto nivel -> Keras.
- A los estudiantes se les presentarán tres problemas:
- Problema 1: (Ejemplo 1 de la conferencia -> Imagen sobre el RHS de este WIKI) y se le pide que realice un pase hacia adelante utilizando los siguientes parámetros (20 minutos para completar):
- Función de activación sigmoide para la capa oculta
- Función de activación sigmoide para la capa externa
- Función de pérdida de MSE
- Problema 2: (Ejemplo 1 de la conferencia), se les pedirá a los estudiantes (con orientación dependiendo de la experiencia de codificación previa) que desarrollen una red neuronal desde cero utilizando solo el módulo Numpy, y las funciones de peso y activación del problema 1 (que son las mismas que el Ejemplo 1 de la conferencia (20 minutos para completar).
- Problema 3: (Ejemplo 1 de la conferencia y usando el mismo ejemplo pero pesos aleatorios), se les pedirá a los estudiantes (con orientación dependiendo de la experiencia de codificación previa) que desarrollen una red neuronal utilizando el módulo Tensorflow 2.X con el módulo de Keras inbuild, y los pesos y funciones de activación del problema 1, y luego utilizando pesos aleatorios (que son los mismos que el Ejemplo 1 de la conferencia: 20 minutos para completar).
- Problema 1: (Ejemplo 1 de la conferencia -> Imagen sobre el RHS de este WIKI) y se le pide que realice un pase hacia adelante utilizando los siguientes parámetros (20 minutos para completar):
- Los subobjetivos para estos tres Problemas, es conseguir que los estudiantes se acostumbren a la estructura y aplicación de conceptos fundamentales (funciones de activación, topología y pérdida) para el aprendizaje profundo.
Tiempo: 60 minutos
| Duración (Min) | Descripción |
|---|---|
| 20 | Problema 1: Implementación del bolígrafo y el papel de un pase hacia adelante (ejemplo de la conferencia) |
| 20 | Problema 2: Desarrollar una red neuronal desde cero usando Numpy (ejemplo de la conferencia) |
| 10 | Problema 3: Desarrollar una red neuronal a partir del uso de Keras (ejemplo de la conferencia con pesos establecidos y pesos aleatorios) |
| 10 | Resumen del proceso de pase hacia adelante |
Tutorial 2 — Derivación y aplicación de la retropropagación
Instrucciones del profesor
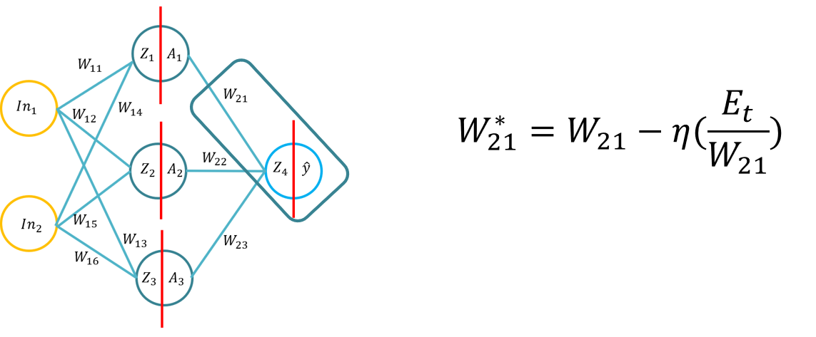
- Este tutorial presentará a los estudiantes los fundamentos del algoritmo de aprendizaje de retropropagación para una red neuronal artificial. Este tutorial consistirá en la derivación del algoritmo de retropropagación utilizando lápiz y papel, luego la aplicación del algoritmo de retropropagación para tres funciones de activación de capas ocultas diferentes (Sigmoid, Tan H y ReLu), utilizando Python con solo la biblioteca Numpy (para la manipulación de matrices) y luego utilizando KERAS.. Esto se basará en la comprensión fundamental de las diferentes funciones de activación cuando una red neuronal aprende y cómo las funciones de activación difieren en la complejidad computacional y la aplicación desde lápiz y papel, para codificar desde cero usando Numpy y luego utilizando un módulo de alto nivel -> Keras.
- Nota: La topología es la misma que la Conferencia 1/Tutorial 1, pero los pesos y las entradas son diferentes, por supuesto, puedes usar los mismos pesos.
- A los estudiantes se les presentarán cuatro problemas (el primero es opcional o como material adicional):
- Problema 1: La derivación del algoritmo de retropropagación (usando la función Sigmoid para las funciones de activación interna y externa y MSE como la función de pérdida), se pedirá a los estudiantes que deriven la fórmula de retropropagación (20 minutos para completar).
- Problema 2: Los estudiantes aplicarán tres funciones de activación para una sola actualización de peso (backpropagation SGD), utilizando lápiz y papel para (20 minutos):
- Sigmoide (capa oculta), sigmoide (capa exterior) y MSE
- Tan H (capa oculta), sigmoide (capa exterior) y MSE
- ReLU (capa oculta), sigmoide (capa exterior) y MSE
- Problema 3: Se pedirá a los estudiantes (con orientación dependiendo de la experiencia de codificación previa) que desarrollen una red neuronal desde cero utilizando solo el módulo Numpy, y las funciones de peso y activación donde se proporciona la opción de seleccionar desde cualquier función de activación de capa oculta para actualizar los pesos utilizando SGD (20 minutos para completar).
- Problema 4: Se pedirá a los estudiantes (con orientación dependiendo de la experiencia de codificación previa) que desarrollen una red neuronal utilizando el módulo Tensorflow 2.X con el módulo de Keras inbuild, y las funciones de peso y activación, y luego usar pesas aleatorias para completar una o varias actualizaciones de peso. Por favor, no como Keras utiliza una pérdida MSE ligeramente diferente, la pérdida se reduce más rápido en el ejemplo de Keras.
- Keras MSE = pérdida = cuadrado(y_true — y_pred)
- Tutorial MSE = pérdida = (cuadrado(y_true — y_pred))*0.5
- Los subobjetivos para estos tres Problemas, es conseguir que los estudiantes entiendan el algoritmo de retropropagación, lo apliquen para que para la sintonización hipermétrica, los estudiantes puedan comprender mejor los efectos del hiperparámetro.
Tiempo: 60 minutos
| Duración (Min) | Descripción |
|---|---|
| 20 (opcional) | Problema 1: derivación de la fórmula de retropropagación utilizando la función Sigmoid para las funciones de activación interna y externa y MSE como función de pérdida (Opcional) |
| 20 | Problema 2: Los estudiantes aplicarán tres funciones de activación para una sola actualización de peso (backpropagation SGD), utilizando lápiz y papel para (20 minutos): |
| 20 | Problema 3: Los estudiantes desarrollarán una red neuronal desde cero utilizando solo el módulo Numpy, donde el usuario puede seleccionar entre cualquiera de las tres funciones de activación de capas ocultas donde el código puede preformar la retropropagación |
| 10 | Problema 4: Los estudiantes utilizarán el módulo Tensorflow 2.X con el módulo inbuild Keras, preformando la retropropagación usando SGD. |
| 10 | Resumen del proceso de pase hacia adelante |
Tutorial 3 — Sintonización de hiperparámetros
Instrucciones del profesor

- Este tutorial presentará a los estudiantes los fundamentos de la sintonización de hiperparámetros para una red neuronal artificial. Este tutorial consistirá en el seguimiento de múltiples hiperparámetros y luego la evaluación utilizando las mismas configuraciones de modelos que la Conferencia (Conferencia 3). Este tutorial se centrará en la modificación sistemática de los hiperparámetros y la evaluación de las parcelas de diagnóstico (utilizando la pérdida, pero esto podría modificarse fácilmente para obtener precisión, ya que es un problema de clasificación) utilizando el conjunto de datos del censo. Al final de este tutorial (los ejemplos paso a paso) se espera que los estudiantes completen una evaluación práctica con evaluación adicional para la equidad (basada en la evaluación del desempeño del subconjunto).
- Notas:
- Hay preprocesamiento realizado en el conjunto de datos (incluido en el cuaderno), sin embargo, este es el mínimo para que el conjunto de datos funcione con la ANN. Esto no es exhaustivo y no incluye ninguna evaluación (sesgo/justicia).
- Utilizaremos gráficas diagnósticas para evaluar el efecto de la sintonización de hiperparámetros y, en particular, un enfoque en la pérdida, donde debe tenerse en cuenta que el módulo que utilizamos para trazar la pérdida es matplotlib.pyplot, por lo que se escala el eje. Esto puede significar que las diferencias significativas pueden parecer no significativas o viceversa al comparar la pérdida de los datos de entrenamiento o prueba.
- Se presentan algunas libertades para andamios, como el uso de Épocas primero (casi como una técnica de regularización) mientras se mantiene el tamaño del lote constante.
- Para proporcionar ejemplos claros (es decir, sobreajuste) algunos ajustes adicionales a otros hiperparámetros pueden haber sido incluidos para proporcionar parcelas diagnósticas claras para ejemplos.
- Una vez que se identificó una capacidad y profundidad razonables, esto, así como otros hiperparámetros, se bloquean para seguir ejemplos siempre que sea posible.
- Finalmente, algunas de las celdas pueden tardar algún tiempo en entrenarse, incluso con acceso a GPU.
- Los estudiantes recibirán varios pasos para el tutorial:
- Paso 1: Algunos preprocesamiento básico para el conjunto de datos del Censo de Adultos
- Paso 2: Sintonización de capacidad y profundidad (incluidos los siguientes ejemplos):
- Sin convergencia
- Inadaptación
- Sobreajuste
- Convergencia
- Paso 3: Épocas (sobre y bajo entrenamiento, sin introducirlo como una técnica de regularización formal)
- Paso 4: Funciones de activación (con respecto al rendimiento — tiempo de entrenamiento y en algunos casos pérdida)
- Paso 5: Tasas de aprendizaje (incluidos los siguientes ejemplos):
- SGD Vanilla
- SGD con decaimiento de la tasa de aprendizaje
- SGD con impulso
- Tasas de aprendizaje adaptativo:
- RMSProp
- AdaGrad
- Adam
- Los subobjetivos para estas cinco partes es proporcionar a los estudiantes ejemplos y experiencia en la sintonización de hiperparámetros y la evaluación de los efectos utilizando parcelas diagnósticas.
Tiempo: 60 minutos
| Duración (Min) | Descripción |
|---|---|
| 5 | Preprocesamiento de los datos |
| 10 | Ajuste de capacidad y profundidad (ajuste por debajo y sobre) |
| 10 | Épocas (bajo y más entrenamiento) |
| 10 | Tamaños de lote (para supresión de ruido) |
| 10 | Funciones de activación (y sus efectos en el rendimiento — tiempo y precisión) |
| 10 | Tasas de aprendizaje (vanilla, LR Decay, Momentum, Adaptive) |
| 5 | Recapitula en algunos hiperparámetros grapas (ReLu, Adam) y la sintonización de otros (capacidad y profundidad). |
Reconocimientos
Keith Quille (TU Dublín, Tallaght Campus) http://keithquille.com
El programa de maestría en IA centrada en el ser humano fue cofinanciado por el Mecanismo «Conectar Europa» de la Unión Europea en virtud de la subvención «CEF-TC-2020-1 Digital Skills 2020-EU-IA-0068».