
Verwaltungsinformationen
| Titel | Tutorial: Grundlagen des Deep Learning |
| Dauer | 180 min (60 min pro Tutorial) |
| Modulen | B |
| Unterrichtstyp | Anleitung |
| Fokussierung | Technisches – Deep Learning |
| Themenbereich | Forward und Backpropagation |
Suchbegriffe
Vorwärtsausbreitung, Backpropagation, Hyperparameter-Tuning,
Lernziele
- Student versteht das Konzept der Forward Propagation
- Schüler erhalten einen Überblick darüber, wie man Backpropagation ableitet
- Student kann Backpropagation beantragen
- der Student lernt, wie man Hyperparameter abstimmt
Erwartete Vorbereitung
Lernveranstaltungen, die vorab abgeschlossen werden müssen
Obligatorisch für Studenten
- John D. Kelleher und Brain McNamee. (2018), Grundlagen des maschinellen Lernens für Predictive Data Analytics, MIT Press.
- Michael Nielsen. (2015), Neural Networks and Deep Learning, 1. Ermittlungspresse, San Francisco CA USA.
- Charu C. Aggarwal. (2018), Neurale Netze und Deep Learning, 1. Springer
- Antonio Gulli, Sujit Pal. Deep Learning mit Keras, Packt, [ISBN: 9781787128422].
Optional für Studenten
- Matrizen Multiplikation
- Erste Schritte mit Numpy
- Kenntnisse der linearen und logistischen Regression
Referenzen und Hintergründe für Studierende
Keine.
Empfohlen für Lehrer
Keine.
Unterrichtsmaterialien
Keine.
Anleitung für Lehrer
Dieses Lernereignis besteht aus drei Sätzen von Tutorials, die grundlegende Deep-Learning-Themen abdecken. Diese Tutorial-Serie besteht darin, einen Überblick über einen Vorwärtspass, die Ableitung von Backpropagation und die Verwendung von Code zu geben, um den Schülern einen Überblick darüber zu geben, was jeder Parameter tut und wie er das Lernen und die Konvergenz eines neuronalen Netzwerks beeinflussen kann:
- Weiterverbreitung: Stift- und Papierbeispiele und Python-Beispiele mit Numpy (für Grundlagen) und Keras, die ein High-Level-Modul zeigen (das Tensorflow 2.X verwendet).
- Ableitung und Anwendung von Backpropagation: Stift- und Papierbeispiele und Python-Beispiele mit Numpy (für Grundlagen) und Keras, die ein High-Level-Modul zeigen (das Tensorflow 2.X verwendet).
- Hyperparameter-Tuning: Keras-Beispiele, die exemplare diagnostische Diagramme hervorheben, die auf den Effekten für die Änderung bestimmter Hyperparameter basieren (unter Verwendung eines HCAIM -Beispieldatensatzes Datensätze für die Lehre ethischer KI (Zensus Dataset).
Lieferscheine (gemäß Vorlesungen)
- Verwendung von Sigmoid in der äußeren Schicht und MSE als Verlustfunktion.
- Bei Zinnbegrenzungen wurde ein einzigartiger Ansatz/Topologie/Problemkontext ausgewählt. Typischerweise würde man mit der Regression für einen Vorwärtspass (mit MSE als Verlustfunktion) und für die Ableitung von Backpropagation beginnen (also eine lineare Aktivierungsfunktion in der Ausgangsschicht haben, wobei dies die Komplexität der Ableitung der Backpropagationsfunktion reduziert), Dann würde man sich typischerweise zu einer binären Klassifikationsfunktion bewegen, mit Sigmoid in der Ausgangsschicht und einer binären Kreuzentropieverlustfunktion. Mit zeitlichen Einschränkungen wird dieser Satz von Vorträgen drei verschiedene Beispiele versteckter Aktivierungsfunktionen verwenden, aber einen Regressionsproblemkontext verwenden. Um die Komplexität einer sigmoiden Aktivierungsfunktion in der Ausgabeschicht, dem in den beiden ersten Vorlesungen dieses Satzes verwendeten Regressionsproblem hinzuzufügen, basiert das Problembeispiel auf einem normalisierten Zielwert (0-1 basierend auf einem prozentualen Gradproblem 0-100 %), so dass Sigmoid als Aktivierungsfunktion in der Ausgabeschicht verwendet wird. Dieser Ansatz ermöglicht es den Schülern, leicht zwischen Regressions- und binären Klassifikationsproblemen zu migrieren, indem sie einfach die Verlustfunktion ändern, wenn ein binäres Klassifikationsproblem verwendet wird oder wenn ein nicht-normalisiertes Regressionsproblem verwendet wird, entfernt der Student einfach die äußere Schichtaktivierungsfunktion.
- Kernkomponenten sind die Anwendung einer High-Level-Bibliothek, in diesem Fall KERAS über die TensorFlow 2.X-Bibliothek.
- Stift und Papier sind optional und werden nur verwendet, um die Vorwärtspass- und Backpropagationsableitung und -anwendung zu zeigen (unter Verwendung der Beispiele aus den Vortragsfolien).
- Python-Code ohne Verwendung von High-Level-Bibliotheken wird verwendet, um zu zeigen, wie einfach ein neuronales Netz ist (unter Verwendung der Beispiele aus den Vortragsfolien). Dies ermöglicht auch eine Diskussion über schnelle numerische/Matrizen-Multiplikation und stellt vor, warum wir GPUs/TPUs als optionales Element verwenden.
- Keras und TensorFlow 2.X werden für alle zukünftigen Beispiele verwendet.
Tutorial 1 – Weiterverbreitung
Anleitung des Lehrers
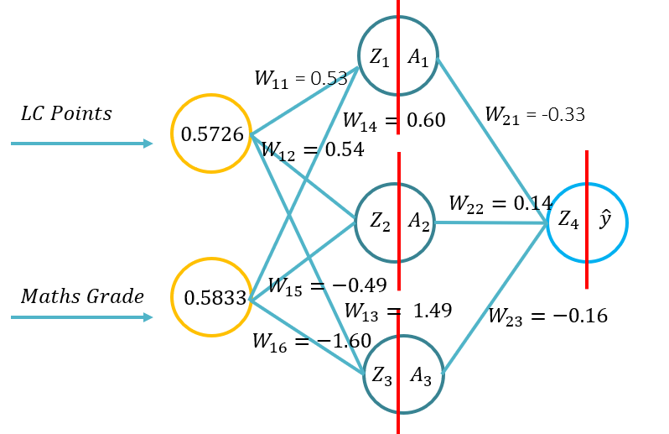
- Dieses Tutorial wird den Schülern die Grundlagen der Forward-Propagation für ein künstliches neuronales Netzwerk vorstellen. Dieses Tutorial besteht aus einem Vorwärtspass mit Stift und Papier, wobei Python nur mit der Numpy-Bibliothek (für Matrizenmanipulation) und dann mit KERAS verwendet wird. Dies wird auf dem grundlegenden Verständnis dessen aufbauen, welche Aktivierungsfunktionen für spezifische Problemkontexte gelten und wie sich die Aktivierungsfunktionen in der Rechenkomplexität und der Anwendung von Stift und Papier unterscheiden, um mit Numpy und dann mit einem High-Level-Modul -> Keras von Grund auf zu codieren.
- Die Studierenden werden mit drei Problemen konfrontiert:
- Problem 1: (Beispiel 1 aus der Vorlesung -> Bild über das RHS dieses WIKI) und gebeten, einen Vorwärtspass mit den folgenden Parametern (20 Minuten zum Abschluss) durchzuführen:
- Sigmoid-Aktivierungsfunktion für die versteckte Schicht
- Sigmoid-Aktivierungsfunktion für die äußere Schicht
- MSE Verlustfunktion
- Problem 2: (Beispiel 1 aus der Vorlesung), werden die Studierenden (mit Anleitung je nach vorheriger Programmiererfahrung) gebeten, ein neuronales Netzwerk von Grund auf neu zu entwickeln, indem nur das Numpy-Modul verwendet wird, und die Gewichte und Aktivierungsfunktionen von Problem 1 (das sind die gleichen wie Beispiel 1 aus der Vorlesung (20 Minuten zu vervollständigen).
- Problem 3: (Beispiel 1 aus der Vorlesung und am gleichen Beispiel, aber zufällige Gewichte) werden die Schüler gebeten (mit Anleitung je nach vorheriger Programmiererfahrung) ein neuronales Netzwerk mit dem Modul Tensorflow 2.X mit dem inbuild Keras Modul und den Gewichten und Aktivierungsfunktionen aus Problem 1 zu entwickeln und dann Zufallsgewichte zu verwenden (die dasselbe sind wie Beispiel 1 aus der Vorlesung: 20 Minuten zu vervollständigen).
- Problem 1: (Beispiel 1 aus der Vorlesung -> Bild über das RHS dieses WIKI) und gebeten, einen Vorwärtspass mit den folgenden Parametern (20 Minuten zum Abschluss) durchzuführen:
- Die Unterziele für diese drei Probleme sind es, die Studierenden an die Struktur und Anwendung grundlegender Konzepte (Aktivierungsfunktionen, Topologie und Verlustfunktionen) für Deep Learning zu gewöhnen.
Uhrzeit: 60 Minuten
| Dauer (Min.) | Beschreibung |
|---|---|
| 20 | Problem 1: Pen & Paper Umsetzung eines Forward Pass (Beispiel aus der Vorlesung) |
| 20 | Problem 2: Entwicklung eines neuronalen Netzwerks von Grund auf mit Numpy (Beispiel aus der Vorlesung) |
| 10 | Problem 3: Entwicklung eines neuronalen Netzes aus Keras (Beispiel aus der Vorlesung mit eingestellten Gewichten und Zufallsgewichten) |
| 10 | Rückblick auf den Forward-Pass-Prozess |
Tutorial 2 – Ableitung und Anwendung der Backpropagation
Anleitung des Lehrers
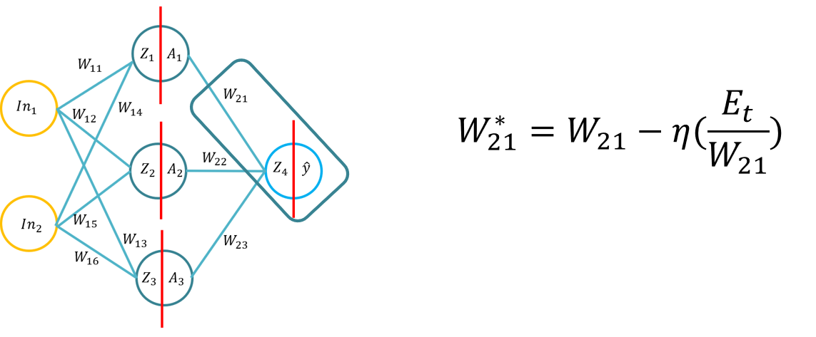
- Dieses Tutorial wird den Schülern die Grundlagen des Backpropagation Lernalgorithmus für ein künstliches neuronales Netzwerk vorstellen. Dieses Tutorial besteht aus der Ableitung des Backpropagation-Algorithmus mit Stift und Papier, dann der Anwendung des Backpropagation-Algorithmus für drei verschiedene Funktionen der versteckten Schicht (Sigmoid, Tan H und ReLu), wobei Python nur mit der Numpy-Bibliothek (für Matrizenmanipulation) und dann mit KERAS verwendet wird. Dies baut auf dem grundlegenden Verständnis unterschiedlicher Aktivierungsfunktionen auf, wenn ein neuronales Netzwerk lernt und wie sich die Aktivierungsfunktionen in der Rechenkomplexität und der Anwendung von Stift und Papier unterscheiden, um mit Numpy und dann mit einem High-Level-Modul -> Keras von Grund auf zu codieren.
- Anmerkung: Die Topologie ist die gleiche wie Vorlesung 1/Tutorial 1, aber die Gewichte und Eingaben sind unterschiedlich, Sie können natürlich die gleichen Gewichte verwenden.
- Die Studierenden werden mit vier Problemen konfrontiert (die erste ist optional oder als zusätzliches Material):
- Problem 1: Bei der Ableitung des Backpropagation-Algorithmus (unter Verwendung der Sigmoid-Funktion für die inneren und äußeren Aktivierungsfunktionen und MSE als Verlustfunktion) werden die Schüler aufgefordert, die Rückvermehrungsformel (20 Minuten zum Abschluss) abzuleiten.
- Problem 2: Die Schüler werden drei Aktivierungsfunktionen für ein einzelnes Gewichtsupdate (SGD-Backpropagation) anwenden, wobei Stift und Papier für (20 Minuten) verwendet werden:
- Sigmoid (Verborgene Schicht), Sigmoid (Außenschicht) und MSE
- Tan H (Verborgene Schicht), Sigmoid (Außenschicht) und MSE
- ReLU (Verborgene Schicht), Sigmoid (Außenschicht) und MSE
- Problem 3: Die Schüler werden gebeten, ein neuronales Netzwerk von Grund auf neu zu entwickeln, indem nur das Numpy-Modul verwendet wird, und die Gewichte und Aktivierungsfunktionen, bei denen die Option zur Auswahl aus einer versteckten Schichtaktivierungsfunktion zur Aktualisierung der Gewichte mit SGD (20 Minuten zum Abschluss) zur Verfügung steht.
- Problem 4: Die Schüler werden gebeten (mit Anleitung, abhängig von der vorherigen Programmiererfahrung), ein neuronales Netzwerk mit dem Modul Tensorflow 2.X mit dem inbuild Keras-Modul und den Gewichten und Aktivierungsfunktionen zu entwickeln und dann Zufallsgewichte zu verwenden, um ein oder mehrere Gewichtsupdates abzuschließen. Bitte nicht, da Keras einen leichten MSE-Verlust verwendet, verringert sich der Verlust im Keras-Beispiel schneller.
- Keras MSE = Verlust = Quadrat(y_true – y_pred)
- Tutorial MSE = Verlust = (quadratisch(y_true – y_pred))*0.5
- Die Unterziele für diese drei Probleme besteht darin, die Schüler dazu zu bringen, den Backpropagation-Algorithmus zu verstehen, ihn anzuwenden, damit die Schüler Hyperparametereffekte besser verstehen können.
Uhrzeit: 60 Minuten
| Dauer (Min.) | Beschreibung |
|---|---|
| 20 (optional) | Problem 1: Ableitung der Rückvermehrungsformel unter Verwendung der Sigmoid-Funktion für die inneren und äußeren Aktivierungsfunktionen und MSE als Verlustfunktion (Optional) |
| 20 | Problem 2: Die Schüler werden drei Aktivierungsfunktionen für ein einzelnes Gewichtsupdate (SGD-Backpropagation) anwenden, wobei Stift und Papier für (20 Minuten) verwendet werden: |
| 20 | Problem 3: Die Schüler werden ein neuronales Netzwerk von Grund auf mit nur dem Numpy-Modul entwickeln, wo der Benutzer aus einer der drei versteckten Schichtaktivierungsfunktionen auswählen kann, bei denen der Code Backpropagation vorformen kann. |
| 10 | Problem 4: Die Schüler werden das Tensorflow 2.X-Modul mit dem inbuild Keras-Modul, Preform Backpropagation mit SGD verwenden. |
| 10 | Rückblick auf den Forward-Pass-Prozess |
Tutorial 3 – Hyperparameter-Tuning
Anleitung des Lehrers

- Dieses Tutorial wird den Schülern die Grundlagen der Hyperparameter-Tuning für ein künstliches neuronales Netzwerk vorstellen. Dieses Tutorial besteht aus dem Nachlaufen mehrerer Hyperparameter und anschließender Auswertung mit den gleichen Modellkonfigurationen wie die Lecture (Vorlesung 3). Dieses Tutorial konzentriert sich auf die systematische Modifikation von Hyperparametern und die Auswertung der diagnostischen Plots (unter Verwendung von Verlusten – aber dies könnte leicht für die Genauigkeit geändert werden, da es sich um ein Klassifikationsproblem handelt) mithilfe des Census Dataset. Am Ende dieses Tutorials (die Schritt-für-Schritt-Beispiele) wird erwartet, dass die Studierenden ein praktisches mit zusätzlicher Bewertung für Fairness (basierend auf der Teilmenge Leistungsbewertung) abschließen.
- Anmerkungen:
- Es wird eine Vorverarbeitung auf dem Datensatz durchgeführt (im Notebook enthalten), dies ist jedoch das Minimum, um den Datensatz zur Arbeit mit der ANN zu bringen. Dies ist nicht umfassend und beinhaltet keine Bewertung (Voreingenommenheit/Fairness).
- Wir werden diagnostische Plots verwenden, um die Wirkung der Hyperparameter-Tuning und insbesondere einen Fokus auf Verlust zu bewerten, wobei zu beachten ist, dass das Modul, das wir verwenden, um den Verlust zu zeichnen, matplotlib.pyplot ist, so dass die Achse skaliert wird. Dies kann bedeuten, dass signifikante Unterschiede beim Vergleich des Verlusts der Trainings- oder Testdaten nicht signifikant erscheinen können oder umgekehrt.
- Einige Freiheiten für Gerüste werden vorgestellt, wie die Verwendung von Epochs zuerst (fast als Regularisierungstechnik) unter Beibehaltung der Batch-Größe konstant.
- Um klare Beispiele (z. B. Overfitting) zu liefern, können einige zusätzliche Anpassungen an andere Hyperparameter aufgenommen worden sein, um klare diagnostische Diagramme für Beispiele bereitzustellen.
- Sobald eine vernünftige Kapazität und Tiefe identifiziert wurde, sind diese sowie andere Hyperparameter für folgende Beispiele gesperrt, wenn möglich.
- Schließlich können einige der Zellen einige Zeit brauchen, um zu trainieren, auch mit GPU-Zugriff.
- Den Schülern werden mehrere Schritte für das Tutorial vorgestellt:
- Schritt 1: Einige grundlegende Vorverarbeitungen für den Adult Census Dataset
- Schritt 2: Kapazitäts- und Tiefenabstimmung (einschließlich der folgenden Beispiele):
- Keine Konvergenz
- Underfitting
- Überfitting
- Konvergenz
- Schritt 3: Epochen (über und unter Ausbildung – ohne es als formale Regularisierungstechnik einzuführen)
- Schritt 4: Aktivierungsfunktionen (in Bezug auf Leistung – Trainingszeit und in einigen Fällen Verlust)
- Schritt 5: Lernquoten (einschließlich der folgenden Beispiele):
- SGD Vanille
- SGD mit Lernrate Zerfall
- SGD mit Impuls
- Adaptive Lernraten:
- RMSProp
- AdaGrad
- Adam
- Die Unterziele für diese fünf Teile sind es, den Schülern Beispiele und Erfahrungen in der Abstimmung von Hyperparametern und der Bewertung der Effekte mittels diagnostischer Plots zu vermitteln.
Uhrzeit: 60 Minuten
| Dauer (Min.) | Beschreibung |
|---|---|
| 5 | Vorverarbeitung der Daten |
| 10 | Kapazitäts- und Tiefenabstimmung (Unter- und Überbestückung) |
| 10 | Epochen (unter und über Ausbildung) |
| 10 | Losgrößen (zur Geräuschunterdrückung) |
| 10 | Aktivierungsfunktionen (und ihre Auswirkungen auf die Leistung – Zeit und Genauigkeit) |
| 10 | Lernraten (Vanille, LR Decay, Momentum, Adaptiv) |
| 5 | Rekapitulieren Sie einige grundlegende Hyperparameter (ReLu, Adam) und die Einstellung anderer (Kapazität und Tiefe). |
Danksagung
Keith Quille (TU Dublin, Tallaght Campus) http://keithquille.com
Das Human-Centered AI Masters-Programm wurde von der Fazilität „Connecting Europe“ der Europäischen Union im Rahmen des Zuschusses „CEF-TC-2020-1 Digital Skills 2020-EU-IA-0068“ kofinanziert.