
Administratívne informácie
| Názov | Výukový program: Základy hlbokého učenia |
| Trvanie | 180 min (60 min na výukový program) |
| Modul | B |
| Druh lekcie | Tutorial |
| Zameranie | Technické – hĺbkové učenie |
| Téma | Predná a spiatočná propagácia |
Kľúčové slová
propagácia dopredu, propagácia chrbta, ladenie hyperparametra,
Vzdelávacie ciele
- študent rozumie konceptu šírenia dopredu
- študent získať pohľad na to, ako odvodiť backpropagation
- študent môže použiť spiatočnú propagáciu
- študent sa učí spôsob ladenia hyperparametrov
Očakávaná príprava
Naučte sa udalosti, ktoré treba dokončiť predtým
Povinné pre študentov
- John D Kelleher a Brain McNamee (2018), Základy strojového učenia pre prediktívnu dátovú analytiku, MIT Press.
- Michael Nielsen. (2015), Neural Networks and Deep Learning (Neurálne siete a hlboké učenie), 1. Kľúčové slová, San Francisco CA USA.
- Charu C. Aggarwal. (2018), Neural Networks and Deep Learning (Neurálne siete a hlboké učenie), 1. Springer
- Antonio Gulli, Sujit Pal. Hlboké učenie s Keras, Packt, [ISBN: 9781787128422].
Voliteľné pre študentov
- Násobenie matríc
- Začať s Numpy
- Znalosť lineárnej a logistickej regresie
Referencie a zázemie pre študentov
Žiadne.
Odporúčané pre učiteľov
Žiadne.
Učebné materiály
Žiadne.
Pokyny pre učiteľov
Táto vzdelávacia udalosť sa skladá z troch súborov tutoriálov pokrývajúcich základné témy hlbokého učenia. Táto tutoriálová séria pozostáva z poskytnutia prehľadu o prechode dopredu, odvodenia spätného šírenia a použitia kódu na poskytnutie prehľadu pre študentov o tom, čo robí každý parameter a ako to môže ovplyvniť učenie a konvergenciu neurónovej siete:
- Šírenie dopredu: Príklady pera a papiera a pythonové príklady používajúce Numpy (pre fundamenty) a Keras zobrazujúci modul na vysokej úrovni (ktorý používa Tensorflow 2.X).
- Odvodenie a uplatňovanie spätného šírenia: Príklady pera a papiera a pythonové príklady používajúce Numpy (pre fundamenty) a Keras zobrazujúci modul na vysokej úrovni (ktorý používa Tensorflow 2.X).
- Ladenie hyperparametrov: Kerasove príklady zdôrazňujúce ukážkové diagnostické grafy založené na účinkoch na zmenu špecifických hyperparametrov (pomocou súboru údajov HCAIM s príkladmi údajov na výučbu etickejumelej inteligencie).
Dodacie listy (podľa prednášok)
- Použitie Sigmoidu vo vonkajšej vrstve a MSE ako funkcie straty.
- S obmedzeniami tine bol vybraný singulárny prístup/topológia/problémový kontext. Typicky by sme začali s regresiou pre prechod dopredu (s MSE ako funkciou straty) a pre odvodenie spätného šírenia (teda s lineárnou aktivačnou funkciou vo výstupnej vrstve, kde to znižuje zložitosť odvodenia funkcie spätného rozmnožovania), potom by sa typicky presunul na binárnu klasifikačnú funkciu, so sigmoidom vo výstupnej vrstve a binárnou funkciou straty krížovej entropie. S časovými obmedzeniami bude táto množina prednášok používať tri rôzne príklady skrytých aktivačných funkcií, ale použije regresný kontext problému. Ak chcete pridať zložitosť sigmoidnej aktivačnej funkcie vo výstupnej vrstve, regresný problém použitý v prvých dvoch prednáškach tejto množiny, príklad problému je založený na normalizovanej cieľovej hodnote (0 – 1 na základe percentuálneho problému 0 – 100 %), takže sigmoid sa používa ako aktivačná funkcia vo výstupnej vrstve. Tento prístup umožňuje študentom ľahko migrovať medzi regresiou a binárnymi klasifikačnými problémami, a to jednoducho zmenou funkcie straty, ak problém binárnej klasifikácie, alebo ak sa používa nenormalizovaný regresný problém, študent jednoducho odstráni funkciu aktivácie vonkajšej vrstvy.
- Základné komponenty sú aplikácia pomocou knižnice vysokej úrovne, v tomto prípade KERAS prostredníctvom knižnice TensorFlow 2.X.
- Pero a papier sú voliteľné a používajú sa len na zobrazenie derivácie a aplikácie prednej časti a spätného šírenia (pomocou príkladov z prednáškových snímok).
- Python kód bez použitia vysokoúrovňových knižníc sa používa na zobrazenie toho, ako jednoduchá neurónová sieť (pomocou príkladov z prednáškových snímok). To tiež umožňuje diskusiu o rýchlom násobení čísel/matrií a predstaví, prečo používame GPU/TPU ako voliteľný prvok.
- Keras a TensorFlow 2.X sa používajú a budú použité pre všetky budúce príklady.
Tutorial 1 – Dopredné šírenie
Pokyny pre učiteľov
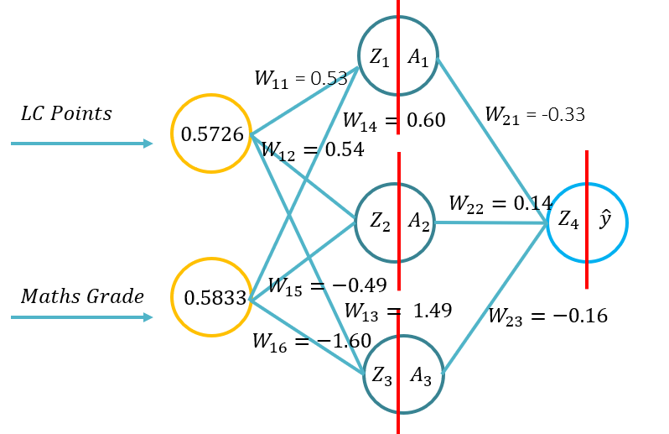
- Tento tutoriál predstaví študentom základy šírenia dopredu pre umelú neurónovú sieť. Tento výukový program bude pozostávať z prednej prihrávky pomocou pera a papiera, pomocou Python len s knižnicou Numpy (pre manipuláciu s matricami) a potom pomocou KERAS.. To bude vychádzať zo základného chápania toho, aké aktivačné funkcie sa vzťahujú na špecifické problémové kontexty a ako sa aktivačné funkcie líšia vo výpočtovej zložitosti a v aplikácii z pera a papiera, na kód od nuly pomocou Numpy a potom pomocou modulu vysokej úrovne -> Keras.
- Študenti budú mať tri problémy:
- Problém 1: (Príklad 1 z prednášky -> Obrázok na RHS tohto WIKI) a požiadal o vykonanie prihrávky s použitím nasledujúcich parametrov (20 minút na dokončenie):
- Sigmoidná aktivačná funkcia pre skrytú vrstvu
- Sigmoidná aktivačná funkcia pre vonkajšiu vrstvu
- Funkcia straty MSE
- Problém 2: (Príklad 1 z prednášky), študenti budú požiadaní (s usmernením v závislosti od predchádzajúcej skúsenosti s kódovaním), aby vyvinuli neurónovú sieť od nuly pomocou modulu Numpy a závažia a aktivačné funkcie z problému 1 (ktoré sú rovnaké ako príklad 1 z prednášky (20 minút na dokončenie).
- Problém 3: (Príklad 1 z prednášky a s použitím rovnakého príkladu, ale náhodných váh), študenti budú požiadaní (s usmernením v závislosti od predchádzajúcej skúsenosti s kódovaním), aby vyvinuli neurónovú sieť pomocou modulu Tensorflow 2.X s modulom inbuild Keras a závažiami a aktivačnými funkciami z problému 1 a potom pomocou náhodných závaží (ktoré sú rovnaké ako príklad 1 z prednášky: 20 minút na dokončenie).
- Problém 1: (Príklad 1 z prednášky -> Obrázok na RHS tohto WIKI) a požiadal o vykonanie prihrávky s použitím nasledujúcich parametrov (20 minút na dokončenie):
- Podcieľom týchto troch problémov je zvyknúť si študentov na štruktúru a aplikáciu základných konceptov (aktivačné funkcie, topológia a stratové funkcie) pre hlboké učenie.
Čas: 60 minút
| Trvanie (Min) | Popis |
|---|---|
| 20 | Problém 1: Pero a papierová implementácia prihrávky (príklad z prednášky) |
| 20 | Problém 2: Rozvoj neurónovej siete od nuly pomocou Numpy (príklad z prednášky) |
| 10 | Problém 3: Rozvoj neurónovej siete z používania Keras (príklad z prednášky s nastavenými závažiami a náhodnými váhami) |
| 10 | Rekapitulácia na proces odovzdávania dopredu |
Tutorial 2 – Odvodenie a aplikácia spätného šírenia
Pokyny pre učiteľov
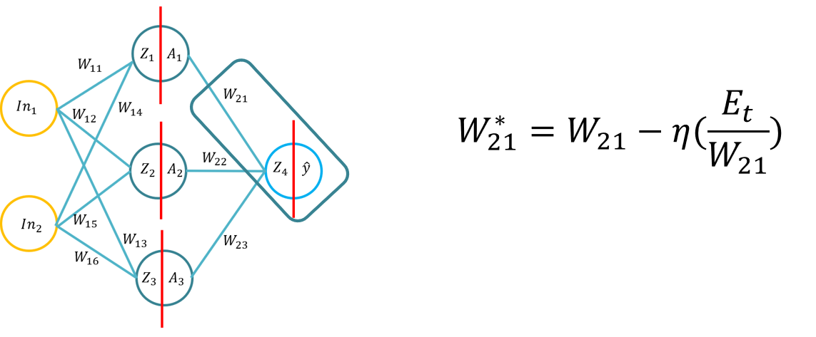
- Tento tutoriál predstaví študentom základy algoritmu spätného šírenia učenia pre umelú neurónovú sieť. Tento výukový program bude pozostávať z odvodenia algoritmu spätného šírenia pomocou pera a papiera, potom aplikácie algoritmu spätného šírenia pre tri rôzne funkcie aktivácie skrytých vrstiev (Sigmoid, Tan H a ReLu), pomocou Pythonu len s knižnicou Numpy (pre manipuláciu s matricami) a potom pomocou KERAS.. To bude stavať na základnom chápaní rôznych aktivačných funkcií, keď sa neurónová sieť dozvie a ako sa aktivačné funkcie líšia vo výpočtovej zložitosti a aplikácii od pera a papiera až po kód od nuly pomocou Numpy a potom pomocou modulu vysokej úrovne -> Keras.
- Poznámka: Topológia je rovnaká ako prednáška 1/Tutorial 1, ale závažia a vstupy sú odlišné, samozrejme môžete použiť rovnaké závažia.
- Študenti budú mať štyri problémy (prvý bude voliteľný alebo ako doplnkový materiál):
- Problém 1: Odvodenie algoritmu spätného šírenia (pomocou funkcie Sigmoid pre vnútorné a vonkajšie aktivačné funkcie a MSE ako funkcie straty) budú študenti požiadaní, aby odvodili vzorec spätného šírenia (20 minút na dokončenie).
- Problém 2: Študenti použijú tri aktivačné funkcie pre jednu aktualizáciu hmotnosti (SGD backpropagation) pomocou pera a papiera po dobu 20 minút:
- Sigmoid (skrytá vrstva), Sigmoid (Outer Layer) a MSE
- Tan H (skrytá vrstva), Sigmoid (Outer Layer) a MSE
- ReLU (skrytá vrstva), Sigmoid (vonkajšia vrstva) a MSE
- Problém 3: Študenti budú požiadaní (s usmernením v závislosti od predchádzajúcej skúsenosti s kódovaním), aby vyvinuli neurónovú sieť od nuly pomocou modulu Numpy a závažia a aktivačné funkcie, kde je k dispozícii možnosť vybrať si z ktorejkoľvek funkcie aktivácie skrytej vrstvy na aktualizáciu váh pomocou SGD (20 minút na dokončenie).
- Problém č. 4: Študenti budú požiadaní (s usmernením v závislosti od predchádzajúcich skúseností s kódovaním) vyvinúť neurónovú sieť pomocou modulu Tensorflow 2.X s modulom Inbuild Keras a závažiami a aktivačnými funkciami a potom pomocou náhodných závaží na dokončenie jednej alebo viacerých hmotnostných aktualizácií. Prosím, nie, pretože Keras používa mierne inú stratu MSE, strata sa znižuje rýchlejšie v príklade Keras.
- Keras MSE = strata = štvorec(y_true – y_pred)
- Tutorial MSE = strata = (štvorec(y_true – y_pred)) *0.5
- Čiastkovými cieľmi pre tieto tri problémy je prinútiť študentov, aby pochopili algoritmus spätného šírenia, aplikovali ho tak, aby pri ladení hypermetra boli študenti schopní lepšie pochopiť účinky hyperparametrov.
Čas: 60 minút
| Trvanie (Min) | Popis |
|---|---|
| 20 (voliteľné) | Problém 1: odvodenie vzorca spätného šírenia pomocou funkcie Sigmoid pre vnútorné a vonkajšie aktivačné funkcie a MSE ako funkcie straty (voliteľné) |
| 20 | Problém 2: Študenti použijú tri aktivačné funkcie pre jednu aktualizáciu hmotnosti (SGD backpropagation) pomocou pera a papiera po dobu 20 minút: |
| 20 | Problém 3: Študenti vyvinú neurónovú sieť od nuly pomocou modulu Numpy, kde si používateľ môže vybrať z ktorejkoľvek z troch skrytých funkcií aktivácie vrstvy, kde kód môže predformovať backpropagáciu |
| 10 | Problém č. 4: Študenti budú používať modul Tensorflow 2.X s modulom Inbuild Keras, predformovať backpropagáciu pomocou SGD. |
| 10 | Rekapitulácia na proces odovzdávania dopredu |
Tutorial 3 – Hyperparameter tuning
Pokyny pre učiteľov

- Tento tutoriál predstaví študentom základy hyperparametrového tunningu pre umelú neurónovú sieť. Tento návod bude pozostávať zo zakončenia viacerých hyperparametrov a potom vyhodnocovania pomocou rovnakých konfigurácií modelov ako prednáška (Lecture 3). Tento návod sa zameria na systematickú modifikáciu hyperparametrov a vyhodnocovanie diagnostických pozemkov (pomocou straty – ale to by mohlo byť ľahko upravené pre presnosť, pretože ide o klasifikačný problém) pomocou súboru údajov sčítania. Na konci tohto tutoriálu (príklady krok za krokom) sa od študentov očakáva, že dokončia praktické hodnotenie spravodlivosti (na základe hodnotenia výkonnosti podsúboru).
- Poznámky:
- Na súbore údajov (zahrnutých v poznámkovom bloku) sa vykonáva predbežné spracovanie, avšak toto je minimum na to, aby sa súbor údajov dostal do práce s ANN. Toto nie je komplexné a nezahŕňa žiadne hodnotenie (strannosť/spravodlivosť).
- Použijeme diagnostické grafy na vyhodnotenie účinku tunningu hyperparametra a najmä zameranie na stratu, kde je potrebné poznamenať, že modul, ktorý používame na vykreslenie straty, je matplotlib.pyplot, takže os je zmenšená. To môže znamenať, že významné rozdiely sa pri porovnávaní straty tréningových alebo testovacích údajov môžu javiť ako nevýznamné alebo naopak.
- Sú prezentované niektoré slobody lešenia, ako napríklad použitie Epochov ako prvé (takmer ako technika regularizácie) pri zachovaní konštantnej veľkosti dávky.
- Na poskytnutie jasných príkladov (t. j. nadmernej montáže) mohli byť zahrnuté niektoré ďalšie vylepšenia k iným hyperparametrom s cieľom poskytnúť jasné diagnostické grafy pre príklady.
- Keď sa zistí primeraná kapacita a hĺbka, tak aj iné hyperparametre, ak je to možné, sú uzamknuté pre nasledujúce príklady.
- Nakoniec, niektoré bunky môžu trvať nejaký čas na trénovanie, dokonca aj s prístupom GPU.
- Študenti budú prezentované s niekoľkými krokmi pre výukový program:
- Krok 1: Niektoré základné predbežné spracovanie súboru údajov o sčítaní dospelých
- Krok 2: Kapacita a hĺbkové ladenie (vrátane nasledujúcich príkladov):
- Žiadna konvergencia
- Nedostatočné vybavenie
- Nadmerná montáž
- Konvergencia
- Krok 3: Epochy (cez a pod odbornou prípravou – bez toho, aby sa zaviedla ako formálna technika legalizácie)
- Krok 4: Aktivačné funkcie (vzhľadom na výkon – čas výcviku a v niektorých prípadoch strata)
- Krok 5: Miera vzdelania (vrátane nasledujúcich príkladov):
- SGD Vanilla
- SGD s rozpadom miery učenia
- SGD s hybnosťou
- Adaptívne miery vzdelávania:
- RMSProp
- AdaGrad
- Adam
- Čiastkovými cieľmi týchto piatich častí je poskytnúť študentom príklady a skúsenosti s tunovaním hyperparametrov a vyhodnocovaním účinkov pomocou diagnostických grafov.
Čas: 60 minút
| Trvanie (Min) | Popis |
|---|---|
| 5 | Predbežné spracovanie údajov |
| 10 | Kapacita a hĺbkové ladenie (pod a cez montáž) |
| 10 | Epochy (pod a cez odbornú prípravu) |
| 10 | Veľkosti šarží (pre potlačenie hluku) |
| 10 | Aktivačné funkcie (a ich vplyv na výkon – čas a presnosť) |
| 10 | Miera vzdelania (vanilla, LR Decay, Momentum, Adaptive) |
| 5 | Rekapitulácia niektorých strižných hyperparametrov (ReLu, Adam) a ladenie iných (kapacita a hĺbka). |
Uznania
Keith Quille (TU Dublin, kampus Tallaght) http://keithquille.com
Program Masters umelej inteligencie zameraný na človeka bol spolufinancovaný z Nástroja Európskej únie na prepájanie Európy v rámci grantu CEF-TC-2020 – 1 Digitálne zručnosti 2020-EU-IA-0068.