
Upravne informacije
| Naslov | Vadnica: Temelj globokega učenja |
| Trajanje | 180 min (60 min na vadnico) |
| Modul | B |
| Vrsta lekcije | Tutorial |
| Osredotočenost | Tehnično – poglobljeno učenje |
| Tema | Naprej in nazaj propagacija |
Ključne besede
širjenje naprej, propagacija nazaj, nastavitev hiperparametra,
Učni cilji
- študent razume koncept nadaljnjega širjenja
- študent dobi pogled na to, kako izpeljati nazaj propagacijo
- študent lahko uporabi backpropagation
- študent se nauči načina uglaševanja hiperparametrov
Pričakovana priprava
Učenje Dogodki, ki jih je treba dokončati pred
Obvezno za študente
- John D Kelleher in Brain McNamee. (2018), Osnove strojnega učenja za napovedno podatkovno analitiko, MIT Press.
- Michael Nielsen. (2015), Neural Networks and Deep Learning, 1. Odločni tisk, San Francisco CA ZDA.
- Charu C. Aggarwal. (2018), Neural Networks and Deep Learning, 1. Springer
- Antonio Gulli, Sujit Pal. Globoko učenje s Kerasom, Packt, [ISBN: 9781787128422].
Neobvezno za študente
- Množenje matrik
- Začetek z Numpyjem
- Poznavanje linearne in logistične regresije
Reference in ozadje za študente
Nobenega.
Priporočeno za učitelje
Nobenega.
Gradivo za učne ure
Nobenega.
Navodila za učitelje
Ta učni dogodek je sestavljen iz treh sklopov vaj, ki zajemajo temeljne teme globokega učenja. Ta tutorialna serija vsebuje pregled naprej prepustnice, izpeljavo backpropagation in uporabo kode, da se zagotovi pregled za študente o tem, kaj vsak parameter počne in kako lahko vpliva na učenje in zbliževanje nevronske mreže:
- Širjenje naprej: Primeri peresa in papirja ter primeri pythona z uporabo Numpy (za osnove) in Keras, ki prikazuje modul na visoki ravni (ki uporablja Tensorflow 2.X).
- Izpeljava in uporaba retropropagacije: Primeri peresa in papirja ter primeri pythona z uporabo Numpy (za osnove) in Keras, ki prikazuje modul na visoki ravni (ki uporablja Tensorflow 2.X).
- Nastavitev hiperparametrov: Primeri Keras, ki poudarjajo vzorčne diagnostične diagrame, ki temeljijo na učinkih spreminjanja specifičnih hiperparametrov (z uporabo nabora podatkov za primer HCAIM za poučevanje etične umetne inteligence (Census Dataset).
Opombe za dostavo (glede na predavanja)
- Uporaba Sigmoida v zunanji plasti in MSE kot funkcije izgube.
- Z omejitvami tina je bil izbran edinstven pristop/topologija/problemski kontekst. Običajno se začne z regresijo za naprej (z MSE kot funkcijo izgube) in za izpeljavo nazaj propagacije (tako da ima linearno aktivacijsko funkcijo v izhodni plasti, kjer to zmanjša kompleksnost izpeljave funkcije backpropagation), nato pa se običajno premakne na binarno klasifikacijsko funkcijo, s sigmoidom v izhodni plasti in binarno funkcijo navzkrižne entropije. S časovnimi omejitvami bo ta niz predavanj uporabil tri različne primere skritih aktivacijskih funkcij, vendar bo uporabil kontekst regresijskega problema. Če želite dodati kompleksnost sigmoidne aktivacijske funkcije v izhodni plasti, regresijsko težavo, uporabljeno v dveh prvih predavanjih tega niza, problemski primer temelji na normalizirani ciljni vrednosti (0–1, ki temelji na odstotku problema 0–100 %), zato se sigmoid uporablja kot aktivacijsko funkcijo v izhodni plasti. Ta pristop omogoča študentom, da enostavno migrirajo med regresijo in binarnimi klasifikacijskimi problemi, tako da preprosto spremenijo funkcijo izgube le, če je problem binarne klasifikacije, ali če se uporablja nenormalizirana regresijska težava, študent preprosto odstrani funkcijo aktivacije zunanjega sloja.
- Ključne komponente so uporaba, z uporabo knjižnice na visoki ravni, v tem primeru KERAS prek knjižnice TensorFlow 2.X.
- Pero in papir sta neobvezna in se uporabljata samo za prikaz izpeljave in uporabe naprej in nazaj (z uporabo primerov iz diapozitivov za predavanje).
- Pythonova koda brez uporabe knjižnic na visoki ravni se uporablja za prikaz, kako preprosta nevronska mreža (z uporabo primerov iz diapozitivov za predavanja). To omogoča tudi razpravo o hitrem množenju številčnih/matrik in predstavimo, zakaj uporabljamo GPU/TPU kot neobvezen element.
- Keras in TensorFlow 2.X se uporabljata za vse prihodnje primere.
Vadnica 1 – Nadaljnje širjenje
Navodila za učitelje
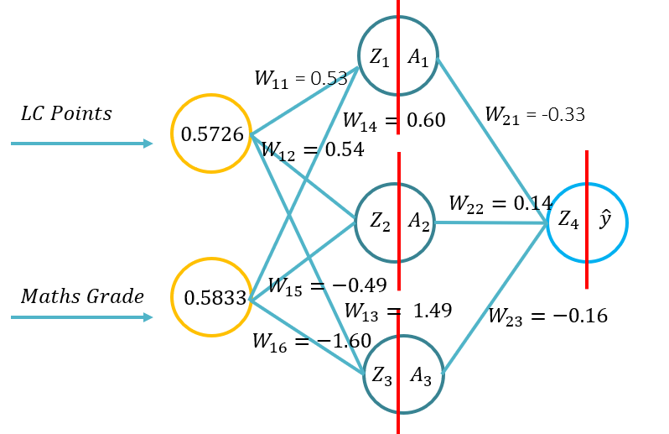
- Ta vadnica bo učencem predstavila osnove nadaljnjega širjenja za umetno nevronsko mrežo. Ta vadnica bo sestavljena iz naprednega prehoda s peresom in papirjem, z uporabo Pythona s samo knjižnico Numpy (za manipulacijo z matricami) in nato z uporabo KERAS-a.. To bo temeljilo na temeljnem razumevanju, katere funkcije aktiviranja veljajo za določene problematične kontekste in kako se funkcije aktiviranja razlikujejo v računalniški kompleksnosti in aplikaciji od peresa in papirja do kode iz nič z uporabo Numpyja in nato z uporabo modula na visoki ravni -> Keras.
- Učenci bodo imeli tri težave:
- Težava 1: (Primer 1 iz predavanja -> Image on the RHS of the WIKI) in prosil za izvedbo prepustnice po naslednjih parametrih (20 minut za dokončanje):
- Sigmoidna aktivacija za skrito plast
- Sigmoidna aktivacija za zunanjo plast
- Funkcija izgube MSE
- Težava 2: (Primer 1 iz predavanja) bodo dijaki (z navodili glede na predhodne izkušnje s kodiranjem) pozvani, naj razvijejo nevronsko mrežo iz nič z uporabo modula Numpy ter uteži in aktivacijske funkcije iz problema 1 (ki so enaki kot primer 1 iz predavanja (20 minut za dokončanje).
- Težava 3: (Primer 1 iz predavanja in z uporabo istega primera, vendar naključnih uteži) bodo študenti pozvani (z navodili glede na predhodne izkušnje kodiranja) razviti nevronsko mrežo z uporabo modula Tensorflow 2.X z vgrajenim modulom Keras in utežmi in aktivacijskimi funkcijami iz problema 1, nato pa z uporabo naključnih uteži (ki so enake kot primer 1 iz predavanja: 20 minut za dokončanje).
- Težava 1: (Primer 1 iz predavanja -> Image on the RHS of the WIKI) in prosil za izvedbo prepustnice po naslednjih parametrih (20 minut za dokončanje):
- Podcilji teh treh problemov so, da se učenci navadijo na strukturo in uporabo temeljnih konceptov (aktivacijske funkcije, topologija in funkcije izgube) za globoko učenje.
Čas: 60 minut
| Trajanje (mini) | Opis |
|---|---|
| 20 | Težava 1: Pero in papir implementacija prepustnice (primer iz predavanja) |
| 20 | Težava 2: Razvoj nevronske mreže iz nič z uporabo Numpyja (primer iz predavanja) |
| 10 | Težava 3: Razvoj nevronske mreže z uporabo Kerasa (primer iz predavanja z določenimi utežmi in naključnimi utežmi) |
| 10 | Ponovite postopek prednjega prehoda |
Vadnica 2 – Izdelava in uporaba backpropagation
Navodila za učitelje
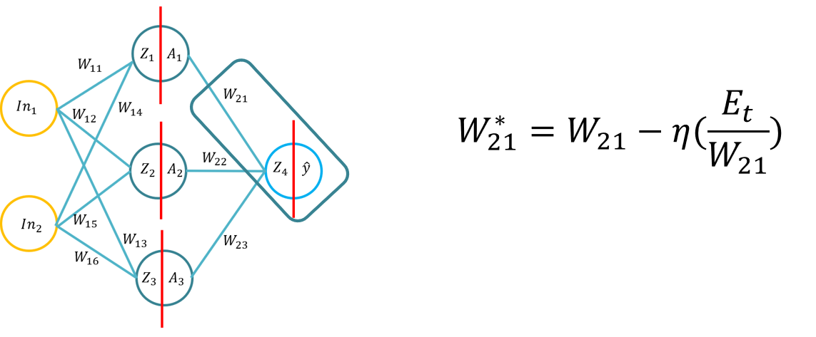
- Ta vadnica bo učencem predstavila osnove algoritma za učenje backpropagation za umetno nevronsko mrežo. Ta vadnica bo sestavljena iz izpeljave algoritma backpropagation z uporabo peresa in papirja, nato pa uporaba algoritma backpropagation za tri različne funkcije aktivacije skrite plasti (Sigmoid, Tan H in ReLu), z uporabo Pythona s samo knjižnico Numpy (za manipulacijo matrik) in nato z uporabo KERAS.. To bo temeljilo na temeljnem razumevanju različnih funkcij aktiviranja, ko se nevronska mreža nauči in kako se funkcije aktiviranja razlikujejo v računalniški kompleksnosti in aplikaciji od peresa in papirja do kode iz nič z uporabo Numpyja in nato z uporabo modula na visoki ravni -> Keras.
- Opomba: Topologija je enaka kot Predavanje 1/Tutorial 1, vendar so uteži in vhodi različni, seveda lahko uporabite enake uteži.
- Dijakom bodo predstavljeni štirje problemi (prva je izbirna ali kot dodatno gradivo):
- Težava 1: Izpeljava algoritma backpropagation (z uporabo funkcije Sigmoid za notranje in zunanje aktivacijske funkcije ter MSE kot funkcije izgube), bodo študenti pozvani, da izpeljejo formulo za povratno propagacijo (20 minut za dokončanje).
- Težava 2: Študenti bodo uporabili tri aktivacijske funkcije za eno posodobitev teže (SGD backpropagation), z uporabo peresa in papirja (20 minut):
- Sigmoid (Skrita plast), Sigmoid (Outer Layer) in MSE
- Tan H (Skrita plast), Sigmoid (Outer Layer) in MSE
- ReLU (Skrita plast), Sigmoid (Outer Layer) in MSE
- Težava 3: Študenti bodo pozvani (z navodili glede na predhodne izkušnje s kodiranjem) za razvoj nevronske mreže iz nič z uporabo modula Numpy ter uteži in aktivacijske funkcije, kjer je na voljo možnost izbire iz katere koli funkcije aktivacije skritega sloja za posodobitev uteži z uporabo SGD (20 minut za dokončanje).
- Težava 4: Študenti bodo pozvani (z navodili glede na predhodne izkušnje kodiranja) za razvoj nevronske mreže z uporabo modula Tensorflow 2.X z vgrajenim modulom Keras in utežmi in aktivacijskimi funkcijami, nato pa z uporabo naključnih uteži za dokončanje ene ali več posodobitev teže. Prosimo, ne glede na to, da Keras uporablja rahlo drugačno izgubo MSE, izguba se v primeru Keras hitreje zmanjša.
- Keras MSE = izguba = kvadrat(y_true – y_pred)
- Vadnica MSE = izguba = (kvadrat(y_true – y_pred))*0.5
- Podcilji za te tri Težave, je, da bi učenci razumeli algoritem backpropagation, ga uporabili, tako da bodo za hipermeter tuning učenci lahko bolje razumeli učinke hiperparametrov.
Čas: 60 minut
| Trajanje (mini) | Opis |
|---|---|
| 20 (neobvezno) | Težava 1: izpeljava formule za povratno propagacijo z uporabo funkcije Sigmoid za notranjo in zunanjo aktivacijsko funkcijo ter MSE kot funkcijo izgube (neobvezno) |
| 20 | Težava 2: Študenti bodo uporabili tri aktivacijske funkcije za eno posodobitev teže (SGD backpropagation), z uporabo peresa in papirja (20 minut): |
| 20 | Težava 3: Študenti bodo razvili nevronsko mrežo iz nič z uporabo modula Numpy, kjer lahko uporabnik izbere katero koli od treh funkcij aktivacije skrite plasti, kjer lahko koda vnaprej oblikuje nazaj propagacijo. |
| 10 | Težava 4: Študenti bodo uporabili modul Tensorflow 2.X z vgrajenim modulom Keras, predoblikovanjem povratne propagacije z uporabo SGD. |
| 10 | Ponovite postopek prednjega prehoda |
Tutorial 3 – Hiperparameter tuning
Navodila za učitelje

- Ta vadnica bo učencem predstavila osnove hiperparametrskega tunninga za umetno nevronsko mrežo. Ta vadnica bo sestavljena iz sledi več hiperparametrov in nato vrednotenja z uporabo enakih konfiguracij modelov kot predavanje (predavanje 3). Ta vadnica se bo osredotočila na sistematično spreminjanje hiperparametrov in vrednotenje diagnostičnih diagramov (z uporabo izgube – vendar je to mogoče enostavno spremeniti zaradi natančnosti, saj gre za težavo s klasifikacijo) z uporabo nabora podatkov popisa. Na koncu te vaje (primeri korak za korakom) se bo od študentov pričakovalo, da dokončajo Praktiko z dodatno oceno pravičnosti (na podlagi podsklopa ocenjevanja uspešnosti).
- Opombe:
- Na naboru podatkov se izvaja predobdelava (vključena v zvezek), vendar je to minimum, da nabor podatkov deluje z ANN. To ni celovito in ne vključuje nobenega vrednotenja (pristranskosti/poštenosti).
- Uporabili bomo diagnostične ploskve za oceno učinka hiperparametrskega tunninga in še posebej poudarek na izgubi, kjer je treba opozoriti, da je modul, ki ga uporabljamo za risanje izgube, matplotlib.pyplot, zato se os zmanjša. To lahko pomeni, da se pri primerjavi izgube podatkov o usposabljanju ali testu lahko pojavijo pomembne razlike ali obratno.
- Predstavljene so nekatere svoboščine za odre, kot je uporaba Epohs najprej (skoraj kot tehnika regularizacije), hkrati pa ohranja konstanto velikosti košare.
- Za zagotovitev jasnih primerov (tj. prevelikega opremljanja) so bili morda vključeni nekateri dodatni popravki na druge hiperparametre, da bi zagotovili jasne diagnostične diagrame za primere.
- Ko je bila ugotovljena razumna zmogljivost in globina, so ta in drugi hiperparametri zaklenjeni za naslednje primere, kjer je to mogoče.
- Končno, nekatere celice lahko traja nekaj časa za usposabljanje, tudi z dostopom do GPU.
- Dijaki bodo predstavili več korakov za vadnico:
- Korak 1: Nekatere osnovne predobdelave za nabor podatkov popisa odraslih
- Korak 2: Nastavitev zmogljivosti in globine (vključno z naslednjimi primeri):
- Brez konvergence
- Nezadostno opremljanje
- Prekomerno opremljanje
- Konvergenca
- Korak 3: Epohe (prek usposabljanja in usposabljanja – ne uvajajo ga kot formalne tehnike regularizacije)
- Korak 4: Aktivacijske funkcije (glede zmogljivosti – čas usposabljanja in v nekaterih primerih izguba)
- Korak 5: Stopnje učenja (vključno z naslednjimi primeri):
- SGD Vanilla
- SGD z upadanjem stopnje učenja
- SGD z zagonom
- Prilagoditvene stopnje učenja:
- RMSProp
- AdaGrad
- Adam
- Podcilji za teh pet delov so, da študentom zagotovijo primere in izkušnje pri uglaševanju hiperparametrov in ocenjevanju učinkov z uporabo diagnostičnih diagramov.
Čas: 60 minut
| Trajanje (mini) | Opis |
|---|---|
| 5 | Predhodna obdelava podatkov |
| 10 | Nastavitev zmogljivosti in globine (pod in nad vgradnjo) |
| 10 | Epohe (pod in nad usposabljanjem) |
| 10 | Velikosti serij (za preprečevanje hrupa) |
| 10 | Aktivacijske funkcije (in njihovi učinki na učinkovitost – čas in natančnost) |
| 10 | Stopnje učenja (vanilla, LR Decay, Momentum, Adaptive) |
| 5 | Ponovite nekaj osnovnih hiperparametrov (ReLu, Adam) in uglaševanje drugih (zmogljivost in globina). |
Priznanja
Keith Quille (TU Dublin, Tallaght Campus) http://keithquille.com
Program Masters umetne inteligence, ki je bil vključen v človeka, je bil sofinanciran z instrumentom za povezovanje Evrope Evropske unije v okviru nepovratnih sredstev (CEF-TC-2020–1 Digital Skills 2020-EU-IA-0068).