
Administratieve informatie
| Titel | Tutorial: De basis van deep learning |
| Looptijd | 180 min (60 min per tutorial) |
| Module | B |
| Type les | Tutorial |
| Focus | Technisch — diep leren |
| Onderwerp | Voor- en achterpropagatie |
Sleutelwoorden
forward propagation, backpropagation,hyperparameter tuning,
Leerdoelen
- student begrijpt het concept van forward propagation
- studenten krijgen inzicht in hoe je backpropagation kunt afleiden
- student kan backpropagation toepassen
- student leert de manier van het afstemmen van hyperparameters
Verwachte voorbereiding
Leren van gebeurtenissen die moeten worden voltooid voordat
Verplicht voor studenten
- John D Kelleher en Brain McNamee. (2018), Fundamentals of Machine Learning voor Predictive Data Analytics, MIT Press.
- Michael Nielsen. (2015), Neural Networks en Deep Learning, 1. Determinatiepers, San Francisco CA USA.
- Charu C. Aggarwal. (2018), Neural Networks en Deep Learning, 1. Springer
- Antonio Gulli, Sujit Pal. Diep leren met Keras, Packt, [ISBN: 9781787128422].
Optioneel voor studenten
- Vermenigvuldiging van matrices
- Aan de slag met Numpy
- Kennis van lineaire en logistieke regressie
Referenties en achtergronden voor studenten
Geen.
Aanbevolen voor docenten
Geen.
Lesmateriaal
Geen.
Instructies voor docenten
Dit Learning Event bestaat uit drie sets van tutorials over fundamentele deep learning onderwerpen. Deze tutorial serie bestaat uit het geven van een overzicht van een voorwaartse pas, de afleiding van backpropagation en het gebruik van code om studenten een overzicht te geven van wat elke parameter doet, en hoe deze het leren en convergentie van een neuraal netwerk kan beïnvloeden:
- Voorwaartse vermeerdering: Pen- en papiervoorbeelden en pythonvoorbeelden met behulp van Numpy (voor fundamentals) en Keras met een module op hoog niveau (die gebruik maakt van Tensorflow 2.X).
- Het afleiden en toepassen van backpropagation: Pen- en papiervoorbeelden en pythonvoorbeelden met behulp van Numpy (voor fundamentals) en Keras met een module op hoog niveau (die gebruik maakt van Tensorflow 2.X).
- Hyperparameter tuning: Keras voorbeelden van voorbeeldige diagnostische plots op basis van de effecten voor het veranderen van specifieke hyperparameters (met behulp van een HCAIM voorbeeld dataset Dataset voor het onderwijzen van ethische AI (Census Dataset).
Opleveringsnota’s (volgens lezingen)
- Gebruik van Sigmoid in de buitenste laag en MSE als verliesfunctie.
- Met tandbeperkingen werd gekozen voor een enkelvoudige benadering/topologie/probleemcontext. Typisch zou men beginnen met regressie voor een voorwaartse pas (met MSE als de verliesfunctie), en voor het afleiden van backpropagation (dus met een lineaire activeringsfunctie in de outputlaag, waar dit de complexiteit van de afleiding van de backpropagation-functie vermindert), dan zou men meestal overgaan naar een binaire classificatiefunctie, met sigmoid in de outputlaag en een binaire cross-entropy verliesfunctie. Met tijdsbeperkingen zal deze reeks lezingen drie verschillende voorbeeldverborgen activeringsfuncties gebruiken, maar zal een regressieprobleemcontext worden gebruikt. Om de complexiteit van een sigmoïde activeringsfunctie in de outputlaag toe te voegen, het regressieprobleem dat wordt gebruikt in de twee eerste lezingen van deze set, is het probleemvoorbeeld gebaseerd op een genormaliseerde doelwaarde (0-1 gebaseerd op een procentuele probleem 0-100 %), dus sigmoïde wordt gebruikt als activeringsfunctie in de outputlaag. Deze aanpak stelt studenten in staat om gemakkelijk te migreren tussen regressie en binaire classificatieproblemen, door simpelweg alleen de verliesfunctie te wijzigen als een binair classificatieprobleem, of als een niet-genormaliseerd regressieprobleem wordt gebruikt, de student eenvoudig de buitenste laagactiveringsfunctie verwijdert.
- Kerncomponenten zijn de toepassing van, met behulp van een high level bibliotheek, in dit geval KERAS via de TensorFlow 2.X bibliotheek.
- Pen en papier zijn optioneel en worden alleen gebruikt om de voorwaartse pas en backpropagation afleiding en toepassing weer te geven (met behulp van de voorbeelden uit de collegedia’s).
- Python-code zonder gebruik van bibliotheken op hoog niveau, wordt gebruikt om te laten zien hoe eenvoudig een neuraal net is (met behulp van de voorbeelden uit de dia’s van de lezing). Dit maakt ook discussie mogelijk over snelle numerieke/matrices vermenigvuldiging en introduceert waarom we GPU’s/TPU’s als optioneel element gebruiken.
- Keras en TensorFlow 2.X worden gebruikt en zullen worden gebruikt voor alle toekomstige voorbeelden.
Tutorial 1 — Voorwaartse voortplanting
Instructies van de leraar
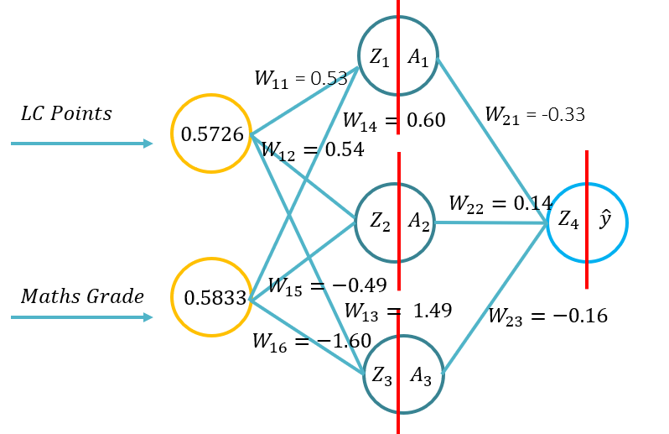
- Deze tutorial zal studenten kennis laten maken met de fundamenten van forward propagation voor een kunstmatig neuraal netwerk. Deze tutorial zal bestaan uit een voorwaartse pas met pen en papier, met Python met alleen de Numpy-bibliotheek (voor matricesmanipulatie) en vervolgens met behulp van KERAS.. Dit zal voortbouwen op het fundamentele begrip van welke activeringsfuncties van toepassing zijn op specifieke probleemcontexten en hoe de activeringsfuncties verschillen in computationele complexiteit en de toepassing van pen en papier, om vanaf nul te coderen met behulp van Numpy en vervolgens met behulp van een module op hoog niveau -> Keras.
- De studenten krijgen drie problemen:
- Probleem 1: (Voorbeeld 1 van de lezing -> Afbeelding op de RHS van deze WIKI) en gevraagd om een voorwaartse pas uit te voeren met behulp van de volgende parameters (20 minuten te voltooien):
- Sigmoïde activeringsfunctie voor de verborgen laag
- Sigmoïde activeringsfunctie voor de buitenste laag
- MSE-verliesfunctie
- Probleem 2: (Voorbeeld 1 van de lezing) worden studenten gevraagd (met begeleiding afhankelijk van de eerdere coderingservaring) om een neuraal netwerk te ontwikkelen vanaf nul met alleen de Numpy-module, en de gewichten en activeringsfuncties van probleem 1 (die hetzelfde zijn als voorbeeld 1 van de lezing (20 minuten te voltooien).
- Probleem 3: (Voorbeeld 1 uit de lezing en met behulp van hetzelfde voorbeeld maar willekeurige gewichten), zullen studenten worden gevraagd (met begeleiding afhankelijk van de eerdere coderingservaring) om een neuraal netwerk te ontwikkelen met behulp van de Tensorflow 2.X-module met de inbuild Keras-module, en de gewichten en activeringsfuncties van probleem 1, en vervolgens met behulp van willekeurige gewichten (die hetzelfde zijn als voorbeeld 1 uit de lezing: 20 minuten te voltooien).
- Probleem 1: (Voorbeeld 1 van de lezing -> Afbeelding op de RHS van deze WIKI) en gevraagd om een voorwaartse pas uit te voeren met behulp van de volgende parameters (20 minuten te voltooien):
- De subdoelen voor deze drie Problemen, is om studenten te laten wennen aan de structuur en toepassing van fundamentele concepten (activatiefuncties, topologie en verliesfuncties) voor deep learning.
Tijd: 60 minuten
| Duur (Min) | Omschrijving |
|---|---|
| 20 | Probleem 1: Pen en Paper implementatie van een forward pass (voorbeeld van de lezing) |
| 20 | Probleem 2: Het ontwikkelen van een neuraal netwerk vanaf nul met behulp van Numpy (voorbeeld uit de lezing) |
| 10 | Probleem 3: Ontwikkelen van een neuraal netwerk van het gebruik van Keras (voorbeeld uit de lezing met vaste gewichten en willekeurige gewichten) |
| 10 | Samenvatting van het forward pass-proces |
Tutorial 2 — Afleiding en toepassing van backpropagation
Instructies van de leraar
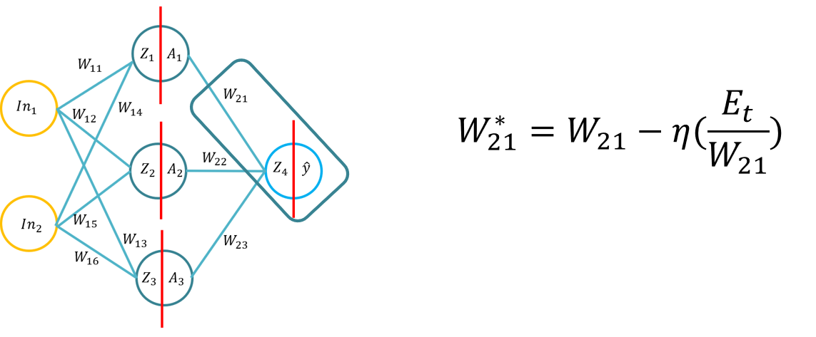
- Deze tutorial zal studenten kennis laten maken met de fundamenten van het backpropagation learning-algoritme voor een kunstmatig neuraal netwerk. Deze tutorial zal bestaan uit het afleiden van het backpropagation-algoritme met behulp van pen en papier, vervolgens de toepassing van het backpropagation-algoritme voor drie verschillende verborgen laagactiveringsfuncties (Sigmoid, Tan H en ReLu), waarbij Python wordt gebruikt met alleen de Numpy-bibliotheek (voor matricesmanipulatie) en vervolgens KERAS. Dit zal voortbouwen op het fundamentele begrip van verschillende activeringsfuncties wanneer een neuraal netwerk leert en hoe de activeringsfuncties verschillen in computationele complexiteit en de toepassing van pen en papier, om vanaf nul te coderen met behulp van Numpy en vervolgens met behulp van een module op hoog niveau -> Keras.
- Opmerking: De topologie is hetzelfde als Lezing 1/Tutorial 1, maar de gewichten en inputs zijn verschillend, je kunt natuurlijk dezelfde gewichten gebruiken.
- De studenten krijgen vier problemen (de eerste is optioneel of als extra materiaal):
- Probleem 1: De afleiding van het backpropagation-algoritme (met behulp van de Sigmoid-functie voor de interne en buitenste activeringsfuncties en MSE als verliesfunctie), zullen studenten worden gevraagd om de backpropagation-formule af te leiden (20 minuten te voltooien).
- Probleem 2: Studenten passen drie activeringsfuncties toe voor een enkele gewichtsupdate (SGD-backpropagation), met pen en papier (20 minuten):
- Sigmoïde (Verborgen laag), Sigmoid (buitenste laag) en MSE
- Tan H (Verborgen laag), Sigmoïde (buitenste laag) en MSE
- ReLU (Verborgen laag), Sigmoid (buitenste laag) en MSE
- Probleem 3: Studenten zullen worden gevraagd (met begeleiding afhankelijk van de eerdere coderingservaring) om een neuraal netwerk vanaf nul te ontwikkelen met alleen de Numpy-module, en de gewichten en activeringsfuncties waarbij de optie om uit een verborgen laagactiveringsfunctie te kiezen wordt verstrekt om de gewichten bij te werken met SGD (20 minuten te voltooien).
- Probleem 4: Studenten zullen worden gevraagd (met begeleiding afhankelijk van de eerdere coderingservaring) om een neuraal netwerk te ontwikkelen met behulp van de Tensorflow 2.X-module met de inbuild Keras-module, en de gewichten en activeringsfuncties, en vervolgens met behulp van willekeurige gewichten om een of meerdere gewichtsupdates te voltooien. Alsjeblieft niet omdat Keras een licht ander MSE-verlies gebruikt, het verlies vermindert sneller in het voorbeeld van Keras.
- Keras MSE = verlies = vierkant(y_true — y_pred)
- Tutorial MSE = verlies = (vierkant(y_true — y_pred))*0.5
- De subdoelen voor deze drie Problemen, is om studenten om het backpropagation algoritme te begrijpen, toe te passen, zodat voor hypermeter tuning, de studenten in staat zullen zijn om hyperparameter effecten beter te begrijpen.
Tijd: 60 minuten
| Duur (Min) | Omschrijving |
|---|---|
| 20 (optioneel) | Probleem 1: afleiding van de backpropagatieformule met behulp van de Sigmoid-functie voor de activeringsfuncties binnen en buiten en MSE als verliesfunctie (optioneel) |
| 20 | Probleem 2: Studenten passen drie activeringsfuncties toe voor een enkele gewichtsupdate (SGD-backpropagation), met pen en papier (20 minuten): |
| 20 | Probleem 3: Studenten zullen vanaf nul een neuraal netwerk ontwikkelen met alleen de Numpy-module, waar de gebruiker kan kiezen uit een van de drie verborgen laagactiveringsfuncties waar de code backpropagation kan voorvormen |
| 10 | Probleem 4: Studenten zullen gebruik maken van de Tensorflow 2.X module met de inbuild Keras module, preform backpropagation met behulp van SGD. |
| 10 | Samenvatting van het forward pass-proces |
Tutorial 3 — Hyperparameter tuning
Instructies van de leraar

- Deze tutorial zal studenten kennis laten maken met de fundamenten van de hyperparameter-tuning voor een kunstmatig neuraal netwerk. Deze tutorial zal bestaan uit het volgen van meerdere hyperparameters en vervolgens evalueren met behulp van dezelfde modellenconfiguraties als de Lezing (Lezing 3). Deze tutorial zal zich richten op de systematische wijziging van hyperparameters en de evaluatie van de diagnostische plots (met verlies — maar dit kan gemakkelijk worden gewijzigd voor nauwkeurigheid omdat het een classificatieprobleem is) met behulp van de Census Dataset. Aan het einde van deze tutorial (de stap voor stap voorbeelden) wordt van studenten verwacht dat ze een Praktisch met aanvullende evaluatie voor eerlijkheid voltooien (op basis van subset prestatie-evaluatie).
- Opmerkingen:
- Er wordt voorbewerking uitgevoerd op de dataset (inbegrepen in het notitieblok), maar dit is het minimum om de dataset te laten werken met de ANN. Dit is niet volledig en omvat geen evaluatie (bias/fairness).
- We zullen diagnostische plots gebruiken om het effect van de hyperparameter af te stemmen en in het bijzonder een focus op verlies, waar moet worden opgemerkt dat de module die we gebruiken om het verlies te plotten is matplotlib.pyplot, dus de as wordt geschaald. Dit kan betekenen dat significante verschillen niet significant lijken of vice versa bij het vergelijken van het verlies van de trainings- of testgegevens.
- Sommige vrijheden voor steigers worden gepresenteerd, zoals het gebruik van Epochs eerst (bijna als een regularisatietechniek) terwijl de Batch-grootte constant blijft.
- Om duidelijke voorbeelden te geven (d.w.z. overfitting) kunnen enkele extra aanpassingen aan andere hyperparameters zijn opgenomen om duidelijke diagnostische plots voor voorbeelden te bieden.
- Zodra een redelijke capaciteit en diepte is vastgesteld, worden deze evenals andere hyperparameters vergrendeld voor het volgen van voorbeelden waar mogelijk.
- Tot slot kunnen sommige cellen enige tijd in beslag nemen om te trainen, zelfs met GPU-toegang.
- De studenten zullen worden gepresenteerd met een aantal stappen voor de tutorial:
- Stap 1: Enkele basisvoorbewerking voor de Adult Census dataset
- Stap 2: Capaciteit en dieptetuning (inclusief de volgende voorbeelden):
- Geen convergentie
- Onderbevestiging
- Overfitting
- Convergentie
- Stap 3: Periodes (over en onder opleiding — zonder de invoering ervan als een formele regularisatietechniek)
- Stap 4: Activeringsfuncties (met betrekking tot prestaties — trainingstijd en in sommige gevallen verlies)
- Stap 5: Leerpercentages (inclusief de volgende voorbeelden):
- SGD Vanilla
- SGD met leersnelheid verval
- SGD met momentum
- Adaptieve leerpercentages:
- RMSProp
- AdaGrad
- Adam
- De subdoelen voor deze vijf delen is om studenten te voorzien van voorbeelden en ervaring in het afstemmen van hyperparameters en het evalueren van de effecten met behulp van diagnostische plots.
Tijd: 60 minuten
| Duur (Min) | Omschrijving |
|---|---|
| 5 | Voorverwerking van de gegevens |
| 10 | Capaciteit en dieptetuning (onder en boven montage) |
| 10 | Periodes (onder en boven opleiding) |
| 10 | Batchgroottes (voor geluidsonderdrukking) |
| 10 | Activeringsfuncties (en hun effecten op prestaties — tijd en nauwkeurigheid) |
| 10 | Leerpercentages (vanille, LR Decay, Momentum, Adaptief) |
| 5 | Neem een samenvatting van sommige niet-hyperparameters (ReLu, Adam) en het afstemmen van anderen (capaciteit en diepte). |
Erkenningen
Keith Quille (TU Dublin, Tallaght Campus) http://keithquille.com
Het Human-Centered AI Masters-programma werd mede gefinancierd door de Connecting Europe Facility van de Europese Unie in het kader van de subsidie CEF-TC-2020-1 Digital Skills 2020-EU-IA-0068.