
Administrativ information
| Titel | Handledning: Grunden för djupinlärning |
| Varaktighet | 180 min (60 min per handledning) |
| Modul | B |
| Typ av lektion | Handledning |
| Fokus | Tekniskt – Djupt lärande |
| Ämne | Fram- och Backpropagation |
Nyckelord
framåtförökning, backpropagation, hyperparameterinställning,
Lärandemål
- studenten förstår begreppet framåtutbredning
- student får syn på hur man härleder backpropagation
- studenten kan ansöka om backpropagation
- studenten lär sig sättet att ställa in hyperparametrar
Förväntad förberedelse
Lärande händelser som ska slutföras innan
Obligatoriskt för studenter
- John D Kelleher och Brain McNamee. (2018), Grundläggande maskininlärning för prediktiv dataanalys, MIT Press.
- Michael Nielsen. (2015), Neurala nätverk och djupt lärande, 1. Beslutande press, San Francisco CA USA.
- Charu C. Aggarwal. (2018), Neurala nätverk och djupt lärande, 1. Springer
- Antonio Gulli och Sujit Pal. Djupinlärning med Keras, Packt, [ISBN: 9781787128422].
Valfritt för studenter
- Multiplikation av matriser
- Komma igång med Numpy
- Kunskap om linjär och logistisk regression
Referenser och bakgrund för studenter
Ingen.
Rekommenderas för lärare
Ingen.
Lektionsmaterial
Ingen.
Instruktioner för lärare
Denna inlärningshändelse består av tre uppsättningar handledning som täcker grundläggande djupinlärning ämnen. Denna handledningsserie består av att ge en översikt över ett framåtpass, härledning av backpropagation och användningen av kod för att ge en översikt för eleverna om vad varje parameter gör, och hur det kan påverka inlärning och konvergens av ett neuralt nätverk:
- Förökning framåt: Exempel på penna och papper och pythonexempel med Numpy (för grundämnen) och Keras som visar en högnivåmodul (som använder Tensorflow 2.X).
- Härleda och tillämpa återutbredning: Exempel på penna och papper och pythonexempel med Numpy (för grundämnen) och Keras som visar en högnivåmodul (som använder Tensorflow 2.X).
- Hyperparameterinställning: Keras exempel belyser exemplariska diagnostiska tomter baserat på effekterna för att ändra specifika hyperparametrar (med hjälp av ett HCAIM- exempeldataset Datauppsättningar för undervisning i etisk AI (Census Dataset).
Anteckningar för leverans (enligt föreläsningar)
- Användning av Sigmoid i det yttre lagret och MSE som förlustfunktion.
- Med tine begränsningar valdes en singular approach/topologi/problemsammanhang. Vanligtvis skulle man börja med regression för ett framåtpass (med MSE som förlustfunktion) och för att härleda tillbakapropagation (således har en linjär aktiveringsfunktion i utgångsskiktet, där detta minskar komplexiteten i härledningen av bakåtpropageringsfunktionen), då skulle man vanligtvis flytta till en binär klassificeringsfunktion, med sigmoid i utgångsskiktet och en binär kors-entropiförlustfunktion. Med tidsbegränsningar kommer denna uppsättning föreläsningar att använda tre olika exempel dolda aktiveringsfunktioner, men kommer att använda ett regressionsproblem sammanhang. För att lägga till komplexiteten hos en sigmoidaktiveringsfunktion i utgångsskiktet, regressionsproblemet som används i de två första föreläsningarna i denna uppsättning, baseras problemexemplet på ett normaliserat målvärde (0–1 baserat på ett procentuellt kvalitetsproblem 0–100 %), vilket innebär att sigmoid används som en aktiveringsfunktion i utgångsskiktet. Detta tillvägagångssätt gör det möjligt för eleverna att enkelt migrera mellan regression och binära klassificeringsproblem, genom att helt enkelt bara ändra förlustfunktionen om ett binärt klassificeringsproblem, eller om ett icke-normaliserat regressionsproblem används, tar studenten helt enkelt bort funktionen för yttre lageraktivering.
- Kärnkomponenter är tillämpningen av, med hjälp av ett högnivåbibliotek, i detta fall KERAS via TensorFlow 2.X-biblioteket.
- Penna och papper är valfria och används endast för att visa fram- och bakpropagationsderivationen och applikationen (med hjälp av exemplen från föreläsningsbilderna).
- Python-kod utan användning av högnivåbibliotek, används för att visa hur enkelt ett neuralt nät (med exemplen från föreläsningsbilderna). Detta möjliggör också diskussion om snabb numerisk/matrismultiplikation och introducerar varför vi använder GPU/TPU som ett valfritt element.
- Keras och TensorFlow 2.X används och kommer att användas för alla framtida exempel.
Handledning 1 – Framåt förökning
Lärarinstruktioner
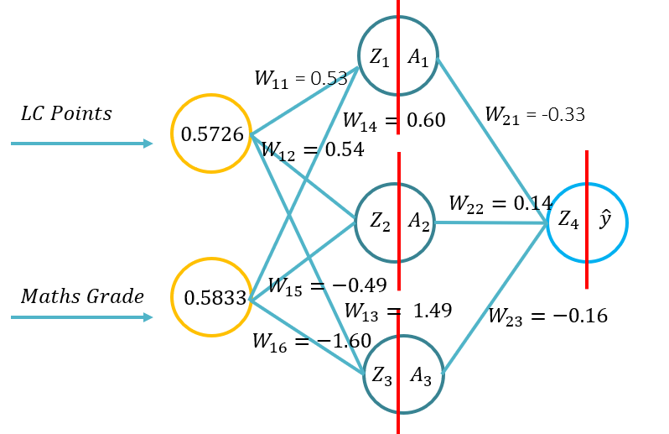
- Denna handledning kommer att introducera eleverna till grunderna för framåtförökning för ett artificiellt neuralt nätverk. Denna handledning kommer att bestå av ett framåtpass med penna och papper, med Python med endast Numpy-biblioteket (för matrismanipulation) och sedan använda KERAS.. Detta kommer att bygga på den grundläggande förståelsen av vilka aktiveringsfunktioner som gäller för specifika problemsammanhang och hur aktiveringsfunktionerna skiljer sig åt i beräkningskomplexitet och applikationen från penna och papper, till kod från grunden med Numpy och sedan använda en högnivåmodul -> Keras.
- Studenterna kommer att presenteras med tre problem:
- Problem 1: (Exempel 1 från föreläsningen -> Bild på RHS av denna WIKI) och bad att genomföra ett framåtpass med följande parametrar (20 minuter att slutföra):
- Sigmoid aktiveringsfunktion för det dolda lagret
- Sigmoid aktiveringsfunktion för det yttre lagret
- Förlustfunktion för mikro- och småföretag
- Problem 2: (Exempel 1 från föreläsningen) kommer studenterna att bli ombedda (med vägledning beroende på tidigare kodningserfarenhet) att utveckla ett neuralt nätverk från grunden med endast Numpy-modulen, och vikter och aktiveringsfunktioner från problem 1 (som är desamma som Exempel 1 från föreläsningen (20 minuter att slutföra).
- Problem 3: (Exempel 1 från föreläsningen och med samma exempel men slumpmässiga vikter) kommer eleverna att bli ombedda (med vägledning beroende på tidigare kodningserfarenhet) att utveckla ett neuralt nätverk med Tensorflow 2.X-modulen med inbuild Keras modul, och vikter och aktiveringsfunktioner från problem 1, och sedan använda slumpmässiga vikter (som är desamma som Exempel 1 från föreläsningen: 20 minuter att slutföra).
- Problem 1: (Exempel 1 från föreläsningen -> Bild på RHS av denna WIKI) och bad att genomföra ett framåtpass med följande parametrar (20 minuter att slutföra):
- Delmålen för dessa tre problem är att få eleverna att vänja sig vid strukturen och tillämpningen av grundläggande begrepp (aktiveringsfunktioner, topologi och förlustfunktioner) för djupinlärning.
Tid: 60 minuter
| Varaktighet (min) | Beskrivning |
|---|---|
| 20 | Problem 1: Penna och pappersimplementering av ett framåtpass (exempel från föreläsningen) |
| 20 | Problem 2: Utveckla ett neuralt nätverk från grunden med hjälp av Numpy (exempel från föreläsningen) |
| 10 | Problem 3: Utveckla ett neuralt nätverk från att använda Keras (exempel från föreläsningen med inställda vikter och slumpmässiga vikter) |
| 10 | Sammanfattning av processen för framåtpass |
Handledning 2 – Derivering och tillämpning av backpropagation
Lärarinstruktioner
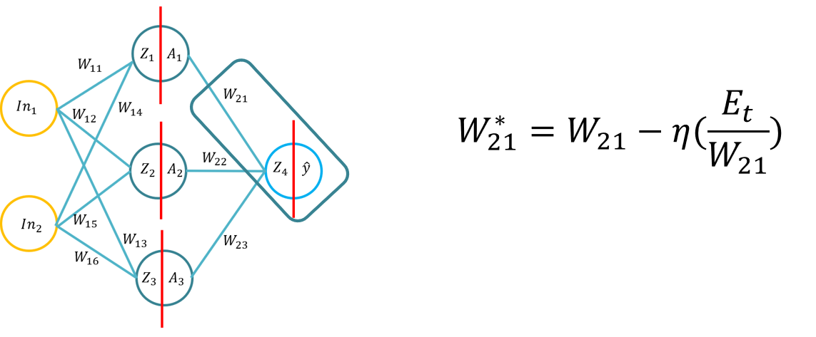
- Denna handledning kommer att introducera eleverna till grunderna i backpropagation inlärningsalgoritmen för ett artificiellt neuralt nätverk. Denna handledning kommer att bestå av härledning av backpropagation algoritmen med hjälp av penna och papper, sedan tillämpningen av backpropagation algoritmen för tre olika dolda lager aktiveringsfunktioner (Sigmoid, Tan H och ReLu), med Python med endast Numpy bibliotek (för matris manipulation) och sedan använda KERAS.. Detta kommer att bygga på den grundläggande förståelsen olika aktiveringsfunktioner när ett neuralt nätverk lär sig och hur aktiveringsfunktionerna skiljer sig åt i beräkningskomplexitet och applikationen från penna och papper, till kod från början med hjälp av Numpy och sedan använda en högnivåmodul -> Keras.
- Anmärkning: Topologin är densamma som Lecture 1/Tutorial 1, men vikterna och ingångarna är olika, du kan naturligtvis använda samma vikter.
- Studenterna kommer att presenteras med fyra problem (den första är valfri eller som ytterligare material):
- Problem 1: Härledning av bakåtpropagationsalgoritmen (med hjälp av Sigmoid-funktionen för de inre och yttre aktiveringsfunktionerna och MSE som förlustfunktion), kommer eleverna att uppmanas att härleda tillbakapropagationsformeln (20 minuter att slutföra).
- Problem 2: Eleverna kommer att tillämpa tre aktiveringsfunktioner för en enda viktuppdatering (SGD backpropagation), med penna och papper i (20 minuter):
- Sigmoid (dold skikt), Sigmoid (ytterskikt) och MSE
- Tan H (dold skikt), Sigmoid (ytterskikt) och MSE
- ReLU (dold skikt), Sigmoid (ytterskikt) och MSE
- Problem 3: Eleverna kommer att bli ombedda (med vägledning beroende på tidigare kodning erfarenhet) att utveckla ett neuralt nätverk från början med endast Numpy modulen, och vikter och aktiveringsfunktioner där alternativet att välja från någon dold lager aktiveringsfunktion tillhandahålls för att uppdatera vikterna med SGD (20 minuter att slutföra).
- Problem 4: Eleverna kommer att bli ombedda (med vägledning beroende på tidigare kodningserfarenhet) att utveckla ett neuralt nätverk med Tensorflow 2.X-modulen med inbuild Keras-modulen och vikter och aktiveringsfunktioner, och sedan använda slumpmässiga vikter för att slutföra en eller flera viktuppdateringar. Vänligen inte eftersom Keras använder en något annorlunda MSE-förlust, minskar förlusten snabbare i exemplet Keras.
- Keras MSE = förlust = square(y_true – y_pred)
- Handledning MSE = förlust = (kvadrat(y_true – y_pred))*0,5
- Delmålen för dessa tre problem, är att få eleverna att förstå backpropagation algoritmen, tillämpa den så att för hypermeter tuning, eleverna kommer att kunna bättre förstå hyperparameter effekter.
Tid: 60 minuter
| Varaktighet (min) | Beskrivning |
|---|---|
| 20 (valfritt) | Problem 1: härledning av ryggpropagationsformeln med hjälp av Sigmoid-funktionen för de inre och yttre aktiveringsfunktionerna och MSE som förlustfunktion (Valfritt) |
| 20 | Problem 2: Eleverna kommer att tillämpa tre aktiveringsfunktioner för en enda viktuppdatering (SGD backpropagation), med penna och papper i (20 minuter): |
| 20 | Problem 3: Eleverna kommer att utveckla ett neuralt nätverk från grunden med hjälp av endast Numpy modulen, där användaren kan välja från någon av tre dolda lager aktiveringsfunktioner där koden kan förforma tillbakapropagation |
| 10 | Problem 4: Eleverna kommer att använda Tensorflow 2.X modulen med inbuild Keras modul, preform backpropagation med SGD. |
| 10 | Sammanfattning av processen för framåtpass |
Tutorial 3 – Hyperparameterjustering
Lärarinstruktioner

- Denna handledning kommer att introducera eleverna till grunderna i hyperparameter tunning för ett artificiellt neuralt nätverk. Denna handledning kommer att bestå av efterföljande av flera hyperparametrar och sedan utvärdering med samma modeller konfigurationer som föreläsningen (Lecture 3). Denna handledning kommer att fokusera på systematisk modifiering av hyperparametrar och utvärdering av de diagnostiska tomterna (med förlust – men detta kan lätt ändras för noggrannhet eftersom det är ett klassificeringsproblem) med hjälp av Census Dataset. I slutet av denna handledning (steg för steg exempel) studenter förväntas slutföra en praktisk med ytterligare utvärdering för rättvisa (baserat på delmängd prestanda utvärdering).
- Anmärkningar:
- Det finns förbehandling på datauppsättningen (ingår i anteckningsboken), men detta är ett minimum för att få datauppsättningen att fungera med ANN. Detta är inte heltäckande och omfattar inte någon utvärdering (grundläggande/rättvishet).
- Vi kommer att använda diagnostiska tomter för att utvärdera effekten av hyperparameter tunning och i synnerhet ett fokus på förlust, där det bör noteras att den modul vi använder för att rita förlusten är matplotlib.pyplot, så axeln skalas. Detta kan innebära att betydande skillnader inte kan framstå som signifikanta eller vice versa när man jämför förlusten av tränings- eller testdata.
- Vissa friheter för byggnadsställningar presenteras, till exempel användningen av Epochs först (nästan som en regulariseringsteknik) samtidigt som Batch-storleken hålls konstant.
- För att ge tydliga exempel (dvs. övermontering) kan några ytterligare tweaks till andra hyperparametrar ha inkluderats för att ge tydliga diagnostiska plottar för exempel.
- När en rimlig kapacitet och djup har identifierats, är detta liksom andra hyperparametrar låsta för följande exempel där det är möjligt.
- Slutligen kan några av cellerna ta lite tid att träna, även med GPU-åtkomst.
- Studenterna kommer att presenteras med flera steg för handledningen:
- Steg 1: Några grundläggande förbehandling för datauppsättningen Vuxenräkning
- Steg 2: Kapacitet och djup tunnning (inklusive följande exempel):
- Ingen konvergens
- Undermontering
- Översittning
- Konvergens
- Steg 3: Epoker (över och under träning – utan att införa det som en formell regleringsteknik)
- Steg 4: Aktiveringsfunktioner (med avseende på prestanda – utbildningstid och i vissa fall förlust)
- Steg 5: Utbildningsnivå (inklusive följande exempel):
- SGD Vanilla
- SGD med inlärningshastighet sönderfall
- SGD med momentum
- Adaptiv inlärningsgrad:
- RMSProp
- AdaGrad
- Adam
- Delmålen för dessa fem delar är att ge studenterna exempel och erfarenhet av tunning hyperparametrar och utvärdera effekterna med hjälp av diagnostiska tomter.
Tid: 60 minuter
| Varaktighet (min) | Beskrivning |
|---|---|
| 5 | Förbehandling av data |
| 10 | Kapacitet och djup tunnning (under och över montering) |
| 10 | Epok (under och över träning) |
| 10 | Satsstorlekar (för bullerdämpning) |
| 10 | Aktiveringsfunktioner (och deras effekter på prestanda – tid och noggrannhet) |
| 10 | Inlärningsfrekvens (vanilj, LR Decay, Momentum, Adaptive) |
| 5 | Recap på några stapelhyperparametrar (ReLu, Adam) och tunnning av andra (kapacitet och djup). |
Erkännanden
Keith Quille (TU Dublin, Tallaght Campus) http://keithquille.com
Masterprogrammet Human-Centered AI har samfinansierats av Fonden för ett sammanlänkat Europa i Europeiska unionen inom ramen för Grant CEF-TC-2020–1 Digital Skills 2020 EU-IA-0068.