
Administrativní informace
| Název | Tutoriál: Základy hlubokého učení |
| Trvání | 180 min (60 min na tutoriál) |
| Modul | B |
| Typ lekce | Tutoriál |
| Soustředění | Technické – hluboké učení |
| Téma | Vpřed a zpětná propagace |
Klíčová slova
množení vpřed, zpětné šíření, ladění hyperparametrů,
Vzdělávací cíle
- student rozumí konceptu šíření vpřed
- student dostane pohled na to, jak odvodit backpropagation
- student může požádat o zpětné šíření
- student se učí způsob ladění hyperparametrů
Očekávaná příprava
Vzdělávací akce, které mají být dokončeny před
Povinné pro studenty
- John D Kelleher a Brain McNamee. (2018), Základy strojového učení pro prediktivní datovou analýzu, MIT Press.
- Michael Nielsen. (2015), neuronové sítě a hluboké učení, 1. Determinační tisk, San Francisco CA USA.
- Charu C. Aggarwal. (2018), Neural Networks and Deep Learning, 1. Springer
- Antonio Gulli, Sujit Pal. Hluboké učení s Keras, Packt, [ISBN: 9781787128422].
Volitelné pro studenty
- Násobení matricí
- Začínáme s Numpy
- Znalost lineární a logistické regrese
Reference a zázemí pro studenty
Žádné.
Doporučeno pro učitele
Žádné.
Materiály pro výuku
Žádné.
Pokyny pro učitele
Tato vzdělávací událost se skládá ze tří sad výukových programů, které pokrývají základní témata hlubokého učení. Tato výuková série se skládá z poskytnutí přehledu o forward passu, odvození zpětného šíření a použití kódu, který poskytuje studentům přehled o tom, co každý parametr dělá, a jak může ovlivnit učení a konvergenci neuronové sítě:
- Šíření vpřed: Příklady pera a papíru a pythonové příklady používající Numpy (pro fundamenty) a Keras zobrazující modul na vysoké úrovni (který používá Tensorflow 2.X).
- Odvození a aplikace zpětného šíření: Příklady pera a papíru a pythonové příklady používající Numpy (pro fundamenty) a Keras zobrazující modul na vysoké úrovni (který používá Tensorflow 2.X).
- Hyperparametrové ladění: Příklady Keras zdůrazňují příkladné diagnostické grafy založené na účincích na změnu specifických hyperparametrů (pomocí souboru dat HCAIM Datové sady pro výuku etické umělé inteligence (sčítání dat).
Poznámky k doručení (podle přednášek)
- Použití Sigmoid ve vnější vrstvě a MSE jako funkce ztráty.
- S omezeními tine byl zvolen singulární přístup/topologie/problémový kontext. Typicky by člověk začal s regresí pro forward pass (s MSE jako ztrátovou funkcí) a pro odvození backpropagation (tedy s lineární aktivační funkcí ve výstupní vrstvě, kde to snižuje složitost derivace funkce backpropagation), pak by se typicky přesunul na binární klasifikační funkci, se sigmoidem ve výstupní vrstvě a binární funkcí křížové ztráty. S časovým omezením bude tato sada přednášek používat tři různé příklady skrytých aktivačních funkcí, ale použije regresní problémový kontext. Pro doplnění složitosti aktivační funkce sigmoid ve výstupní vrstvě, regresního problému použitého ve dvou prvních přednáškách této sady je příklad problému založen na normalizované cílové hodnotě (0–1 na základě problému 0–100 %), takže sigmoid se používá jako aktivační funkce ve výstupní vrstvě. Tento přístup umožňuje studentům snadno migrovat mezi regresní a binární klasifikační problémy, jednoduše změnou funkce ztráty pouze v případě, že problém binární klasifikace, nebo je-li použit nenormalizovaný regresní problém, student jednoduše odstraní funkci aktivace vnější vrstvy.
- Základní komponenty jsou aplikace knihovny na vysoké úrovni, v tomto případě KERAS prostřednictvím knihovny TensorFlow 2.X.
- Pero a papír jsou volitelné a slouží pouze k zobrazení odvození a aplikace forward pass a backpropagation (pomocí příkladů z přednáškových snímků).
- Python kód bez použití knihoven na vysoké úrovni, slouží k tomu, aby ukázal, jak jednoduchá neuronová síť (pomocí příkladů z přednáškových snímků). To také umožňuje diskusi o rychlé numerické/matrices násobení a představit, proč používáme GPU/TPU jako volitelný prvek.
- Keras a TensorFlow 2.X se používají a budou použity pro všechny budoucí příklady.
Návod 1 – Propagace vpřed
Pokyny pro učitele
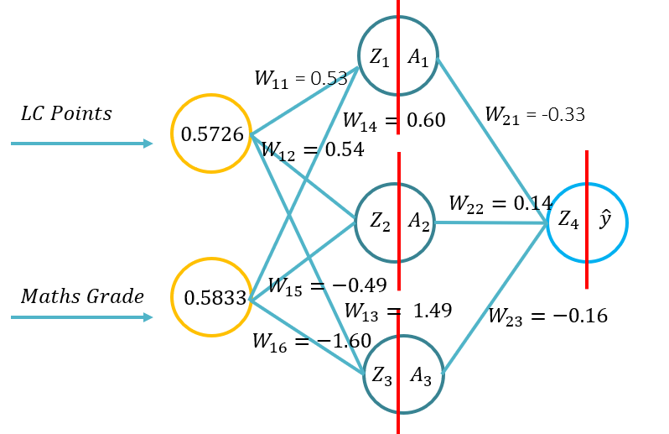
- Tento tutoriál seznámí studenty se základy šíření vpřed pro umělou neuronovou síť. Tento tutoriál se bude skládat z předávacího průchodu pomocí pera a papíru, pomocí Pythonu pouze s knihovnou Numpy (pro manipulaci s maticemi) a pak pomocí KERASu.. To bude vycházet ze základního pochopení toho, jaké aktivační funkce se vztahují na konkrétní problémové kontexty a jak se aktivační funkce liší výpočetní složitostí a aplikací od pera a papíru, až po kódování od nuly pomocí Numpy a pak pomocí modulu na vysoké úrovni -> Keras.
- Studenti budou mít tři problémy:
- Problém 1: (Příklad 1 z přednášky -> Obrázek na RHS tohoto WIKI) a požádal o provedení průjezdu dopředu pomocí následujících parametrů (20 minut k dokončení):
- Funkce aktivace sigmoidů pro skrytou vrstvu
- Sigmoid aktivační funkce pro vnější vrstvu
- Funkce ztráty MSE
- Problém č. 2: (Příklad 1 z přednášky) budou studenti požádáni (s pokyny v závislosti na předchozí zkušenosti s kódováním) o vytvoření neuronové sítě od nuly pomocí modulu Numpy a hmotností a aktivačních funkcí z problému 1 (které jsou stejné jako příklad 1 z přednášky (20 minut dokončit).
- Problém 3: (Příklad 1 z přednášky a pomocí stejného příkladu, ale náhodných vah), budou studenti požádáni (s pokyny v závislosti na předchozí zkušenosti s kódováním) o vytvoření neuronové sítě pomocí modulu Tensorflow 2.X s vestavěným modulem Keras a závaží a aktivačních funkcí z problému 1 a poté pomocí náhodných vah (které jsou stejné jako příklad 1 z přednášky: 20 minut k dokončení).
- Problém 1: (Příklad 1 z přednášky -> Obrázek na RHS tohoto WIKI) a požádal o provedení průjezdu dopředu pomocí následujících parametrů (20 minut k dokončení):
- Dílčí cíle pro tyto tři problémy, je, aby si studenti zvykli na strukturu a aplikaci základních konceptů (aktivační funkce, topologie a ztrátové funkce) pro hluboké učení.
Čas: 60 minut
| Doba trvání (Min) | Popis |
|---|---|
| 20 | Problém 1: Realizace pera a papíru vpřed (příklad z přednášky) |
| 20 | Problém č. 2: Vývoj neuronové sítě od nuly pomocí Numpy (příklad z přednášky) |
| 10 | Problém 3: Vývoj neuronové sítě z použití Keras (příklad z přednášky s nastavenými závažími a náhodnými závažími) |
| 10 | Rekapitulace procesu předávání dopředu |
Výukový program 2 – Derivation a aplikace backpropagation
Pokyny pro učitele
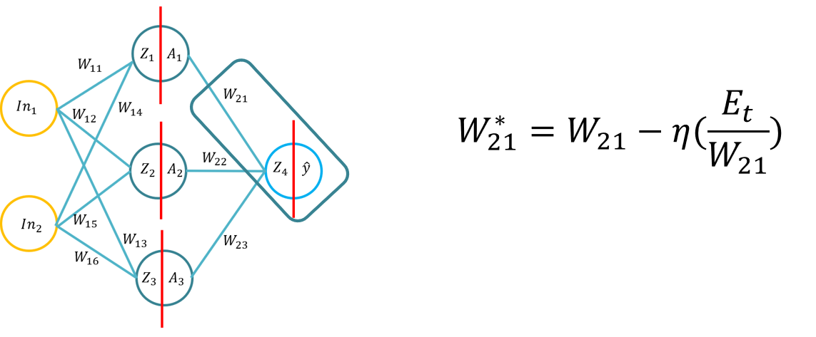
- Tento tutoriál seznámí studenty se základy algoritmu zpětného šíření učení pro umělou neuronovou síť. Tento návod se bude skládat z odvození algoritmu backpropagation pomocí pera a papíru, pak aplikace algoritmu backpropagation pro tři různé funkce aktivace skryté vrstvy (Sigmoid, Tan H a ReLu), pomocí Pythonu pouze s Numpy knihovnou (pro manipulaci s maticemi) a pak pomocí KERAS.. To bude stavět na základním pochopení různých aktivačních funkcí, když se neuronová síť dozví, jak se aktivační funkce liší výpočetní složitostí a aplikací od pera a papíru, až po kódování od nuly pomocí Numpy a pak pomocí modulu na vysoké úrovni -> Keras.
- Poznámka: Topologie je stejná jako přednáška 1/Tutorial 1, ale váhy a vstupy jsou různé, samozřejmě můžete použít stejné váhy.
- Studenti budou prezentováni se čtyřmi problémy (první je volitelný nebo jako další materiál):
- Problém 1: Odvození algoritmu zpětného šíření (pomocí funkce Sigmoid pro vnitřní a vnější aktivační funkce a MSE jako funkce ztráty) budou studenti požádáni, aby odvodili vzorec zpětného šíření (20 minut k dokončení).
- Problém č. 2: Studenti budou aplikovat tři aktivační funkce pro jednu aktualizaci hmotnosti (SGD backpropagation), pomocí pera a papíru po dobu (20 minut):
- Sigmoid (Skrytá vrstva), Sigmoid (Vnější vrstva) a MSE
- Tan H (Skrytá vrstva), Sigmoid (Vnější vrstva) a MSE
- ReLU (Skrytá vrstva), Sigmoid (Vnější vrstva) a MSE
- Problém 3: Studenti budou požádáni (s pokyny v závislosti na předchozí zkušenosti s kódováním) o vytvoření neuronové sítě od nuly pomocí modulu Numpy a závaží a aktivačních funkcí, kde je k dispozici možnost volby z libovolné funkce aktivace jedné skryté vrstvy pro aktualizaci závaží pomocí SGD (20 minut k dokončení).
- Problém č. 4: Studenti budou požádáni (s pokyny v závislosti na předchozí zkušenosti s kódováním), aby vyvinuli neuronovou síť pomocí modulu Tensorflow 2.X s vestavěným modulem Keras a váhami a aktivačními funkcemi a poté pomocí náhodných vah k dokončení jedné nebo několika aktualizací hmotnosti. Prosím, ne, protože Keras používá mírně jinou ztrátu MSE, ztráta se snižuje rychleji v příkladu Keras.
- Keras MSE = ztráta = čtverec(y_true – y_pred)
- Tutorial MSE = ztráta = (čtverec (y_true – y_pred))*0.5
- Dílčí cíle pro tyto tři problémy, je přimět studenty, aby pochopili algoritmus zpětného šíření, aplikují jej tak, aby pro ladění hypermetrů byli studenti schopni lépe porozumět efektům hyperparametru.
Čas: 60 minut
| Doba trvání (Min) | Popis |
|---|---|
| 20 (volitelné) | Problém 1: odvození vzorce zpětného šíření pomocí funkce Sigmoid pro vnitřní a vnější aktivační funkce a MSE jako funkce ztráty (volitelné) |
| 20 | Problém č. 2: Studenti budou aplikovat tři aktivační funkce pro jednu aktualizaci hmotnosti (SGD backpropagation), pomocí pera a papíru po dobu (20 minut): |
| 20 | Problém 3: Studenti budou rozvíjet neuronovou síť od nuly pouze pomocí modulu Numpy, kde si uživatel může vybrat z kterékoli ze tří aktivačních funkcí skryté vrstvy, kde kód může předformulovat zpětné šíření |
| 10 | Problém č. 4: Studenti budou používat Tensorflow 2.X modul s vestavěným Keras modul, předformulovat backpropagace pomocí SGD. |
| 10 | Rekapitulace procesu předávání dopředu |
Návod 3 – Hyperparametr ladění
Pokyny pro učitele

- Tento tutoriál seznámí studenty se základy hyperparametrového ladění pro umělou neuronovou síť. Tento tutoriál se bude skládat ze sledování více hyperparametrů a následného vyhodnocení pomocí stejných konfigurací modelů jako přednáška (přednáška 3). Tento výukový program se zaměří na systematickou modifikaci hyperparametrů a vyhodnocení diagnostických ploch (pomocí ztráty – ale to by mohlo být snadno upraveno pro přesnost, protože se jedná o problém klasifikace) pomocí sčítání dat. Na konci tohoto tutoriálu (příklady krok za krokem) se očekává, že studenti dokončí Praktický s dodatečným hodnocením spravedlnosti (na základě podskupiny hodnocení výkonnosti).
- Poznámky:
- Na datové sadě (zahrnuté v poznámkovém bloku) se provádí předzpracování, ale to je minimum pro to, aby datová sada fungovala s ANN. To není komplexní a nezahrnuje žádné hodnocení (bias/fairness).
- Použijeme diagnostické grafy k vyhodnocení účinku hyperparametrového ladění a zejména zaměření na ztrátu, kde je třeba poznamenat, že modul, který používáme k vykreslení ztráty, je matplotlib.pyplot, čímž je osa zmenšena. To může znamenat, že významné rozdíly se při porovnávání ztráty tréninkových nebo zkušebních údajů nemusí zdát významné nebo naopak.
- Některé svobody pro lešení jsou prezentovány, jako je použití epoch jako první (téměř jako technika regularizace) při zachování velikosti dávky konstantní.
- Pro poskytnutí jasných příkladů (tj. převybavení) mohly být zahrnuty některé další úpravy k jiným hyperparametrům, které by poskytly jasné diagnostické grafy pro příklady.
- Jakmile byla zjištěna přiměřená kapacita a hloubka, jsou tato i další hyperparametry uzamčeny pro následující příklady, je-li to možné.
- Konečně, některé buňky mohou trvat nějaký čas trénovat, a to i s přístupem GPU.
- Studenti budou prezentováni s několika kroky pro tutoriálu:
- Krok 1: Některé základní předzpracování datového souboru sčítání dospělých
- Krok 2: Kapacita a hloubkové ladění (včetně následujících příkladů):
- Žádná konvergence
- Nedostatečné vybavení
- Přestrojení
- Konvergence
- Krok 3: Epochy (nad a pod výcvikem – aniž by bylo zavedeno jako formální regularizační technika)
- Krok 4: Aktivační funkce (s ohledem na výkon – dobu tréninku a v některých případech ztrátu)
- Krok 5: Míra učení (včetně těchto příkladů):
- SGD Vanilka
- SGD s rozkladem míry učení
- SGD s hybností
- Míra adaptivního učení:
- RMSProp
- AdaGrad
- Adam
- Dílčí cíle pro těchto pět částí je poskytnout studentům příklady a zkušenosti s laděním hyperparametrů a vyhodnocování účinků pomocí diagnostických plotů.
Čas: 60 minut
| Doba trvání (Min) | Popis |
|---|---|
| 5 | Předběžné zpracování údajů |
| 10 | Kapacita a hloubka ladění (pod a over fit) |
| 10 | Epochy (pod a nad tréninkem) |
| 10 | Velikosti šarží (pro potlačení šumu) |
| 10 | Aktivační funkce (a jejich vliv na výkon – čas a přesnost) |
| 10 | Míra učení (vanilla, LR Decay, Momentum, Adaptive) |
| 5 | Rekapitulujte některé základní hyperparametry (ReLu, Adam) a ladění jiných (kapacita a hloubka). |
Potvrzení
Keith Quille (TU Dublin, Tallaght Campus) http://keithquille.com
Program Human-Centered AI Masters byl spolufinancován Nástrojem Evropské unie pro propojení Evropy v rámci grantu CEF-TC-2020–1 Digitální dovednosti 2020-EU-IA-0068.