
Informations administratives
| Titre | Tutoriel: Fondamental de l’apprentissage profond |
| Durée | 180 min (60 min par tutoriel) |
| Module | B |
| Type de leçon | Tutoriel |
| Focus | Technique — Deep Learning |
| Sujet | Vers l’avant et rétropropagation |
Mots-clés
propagation vers l’avant, rétropropagation, réglage hyperparamètre,
Objectifs d’apprentissage
- L’étudiant comprend le concept de propagation vers l’avant
- L’étudiant obtient une vue sur la façon de dériver rétropropagation
- L’étudiant peut appliquer la rétropropagation
- L’étudiant apprend la façon de régler les hyperparamètres
Préparation prévue
Événements d’apprentissage à compléter avant
Obligatoire pour les étudiants
- John D Kelleher et Brain McNamee. (2018), Fondamentals of Machine Learning for Predictive Data Analytics, MIT Press.
- Michael Nielsen. (2015), Réseaux neuronaux et apprentissage profond, 1. Presse de détermination, San Francisco CA USA.
- Charu C. Aggarwal. (2018), Réseaux neuronaux et apprentissage profond, 1. Springer
- Antonio Gulli, Sujit Pal. Apprentissage profond avec Keras, Packt, [ISBN: 9781787128422].
Optionnel pour les étudiants
- Multiplication des matrices
- Commencer avec Numpy
- Connaissance de la régression linéaire et logistique
Références et antécédents pour les étudiants
Aucun.
Recommandé pour les enseignants
Aucun.
Matériel de leçon
Aucun.
Instructions pour les enseignants
Cet événement d’apprentissage se compose de trois séries de tutoriels couvrant des sujets fondamentaux d’apprentissage profond. Cette série de tutoriels consiste à fournir une vue d’ensemble d’une passe avant, la dérivation de la rétropropagation et l’utilisation du code pour fournir une vue d’ensemble pour les étudiants sur ce que fait chaque paramètre, et comment il peut affecter l’apprentissage et la convergence d’un réseau de neurones:
- Propagation vers l’avant: Exemples de stylo et de papier, et exemples de python utilisant Numpy (pour les fondamentaux) et Keras montrant un module de haut niveau (qui utilise Tensorflow 2.X).
- Dérivation et application de la rétropropagation: Exemples de stylo et de papier, et exemples de python utilisant Numpy (pour les fondamentaux) et Keras montrant un module de haut niveau (qui utilise Tensorflow 2.X).
- Réglage hyperparamètre: Des exemples de Keras mettant en évidence des diagrammes diagnostiques exemplaires basés sur les effets de la modification d’hyperparamètres spécifiques (en utilisant un exemple HCAIM ensemble de données ensemble de données pour l’enseignement de l’IA éthique (ensemble de données de recensement).
Notes pour la livraison (selon les conférences)
- Utilisation de Sigmoid dans la couche externe et MSE comme fonction de perte.
- Avec des limites, une approche/topologie/contexte singulier a été sélectionnée. Typiquement, on commencerait par une régression pour une passe avant (avec MSE comme fonction de perte), et pour dériver la rétropropagation (ayant ainsi une fonction d’activation linéaire dans la couche de sortie, où cela réduit la complexité de la dérivation de la fonction de rétropropagation), puis on passerait généralement à une fonction de classification binaire, avec sigmoïde dans la couche de sortie, et une fonction binaire de perte d’entropie croisée. Avec des contraintes de temps, cet ensemble de conférences utilisera trois fonctions d’activation cachées, mais utilisera un contexte de problème de régression. Pour ajouter la complexité d’une fonction d’activation sigmoïde dans la couche de sortie, le problème de régression utilisé dans les deux premières conférences de cet ensemble, l’exemple de problème est basé sur une valeur cible normalisée (0-1 basée sur un pourcentage de problème de grade 0-100 %), donc sigmoïde est utilisé comme une fonction d’activation dans la couche de sortie. Cette approche permet aux étudiants de migrer facilement entre les problèmes de régression et de classification binaire, en changeant simplement la fonction de perte si un problème de classification binaire, ou si un problème de régression non normalisé est utilisé, l’étudiant supprime simplement la fonction d’activation de la couche externe.
- Les composants de base sont l’application, à l’aide d’une bibliothèque de haut niveau, dans ce cas KERAS via la bibliothèque TensorFlow 2.X.
- Le stylo et le papier sont facultatifs et ne sont utilisés que pour montrer la dérivation et l’application de la passe avant et de la rétropropagation (en utilisant les exemples des diapositives de conférence).
- Le code Python sans l’utilisation de bibliothèques de haut niveau, est utilisé pour montrer à quel point un réseau neuronal simple (en utilisant les exemples des diapositives de conférence). Cela permet également de discuter de la multiplication numérique/matrices rapide et d’introduire pourquoi nous utilisons les GPU/TPU comme élément optionnel.
- Keras et TensorFlow 2.X sont utilisés et seront utilisés pour tous les exemples futurs.
Tutoriel 1 — propagation en avant
Instructions de l’enseignant
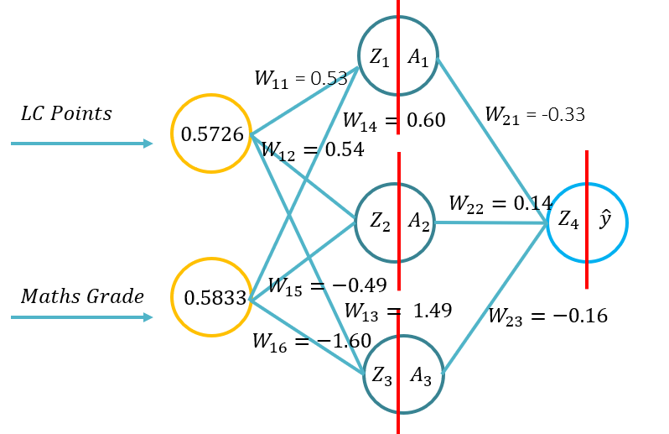
- Ce tutoriel présentera aux étudiants les fondamentaux de la propagation vers l’avant pour un réseau de neurones artificiels. Ce tutoriel consistera en un pass vers l’avant en utilisant le stylo et le papier, en utilisant Python avec uniquement la bibliothèque Numpy (pour la manipulation des matrices) puis en utilisant KERAS. Cela s’appuiera sur la compréhension fondamentale de quelles fonctions d’activation s’appliquent à des contextes de problèmes spécifiques et comment les fonctions d’activation diffèrent dans la complexité informatique et l’application du stylo et du papier, pour coder à partir de zéro en utilisant Numpy, puis en utilisant un module de haut niveau -> Keras.
- Les étudiants seront confrontés à trois problèmes:
- Problème 1: (Exemple 1 de la conférence -> Image sur le RHS de ce WIKI) et demandé d’effectuer une passe en avant en utilisant les paramètres suivants (20 minutes à compléter):
- Fonction d’activation sigmoïde pour la couche cachée
- Fonction d’activation sigmoïde pour la couche externe
- Fonction de perte MSE
- Problème 2: (Exemple 1 de la conférence), les étudiants seront invités (avec des conseils en fonction de l’expérience de codage préalable) à développer un réseau de neurones à partir de zéro en utilisant uniquement le module Numpy, et les poids et les fonctions d’activation du problème 1 (qui sont les mêmes que l’exemple 1 de la conférence (20 minutes à compléter).
- Problème 3: (Exemple 1 de la conférence et en utilisant le même exemple mais des poids aléatoires), les étudiants seront invités (avec des conseils en fonction de l’expérience de codage préalable) à développer un réseau neuronal en utilisant le module Tensorflow 2.X avec le module inbuild Keras, et les poids et les fonctions d’activation du problème 1, puis en utilisant des poids aléatoires (qui sont les mêmes que l’exemple 1 de la conférence: 20 minutes à compléter).
- Problème 1: (Exemple 1 de la conférence -> Image sur le RHS de ce WIKI) et demandé d’effectuer une passe en avant en utilisant les paramètres suivants (20 minutes à compléter):
- Les sous-objectifs de ces trois problèmes, c’est de s’habituer à la structure et à l’application de concepts fondamentaux (fonctions d’activation, fonctions de topologie et de perte) pour l’apprentissage profond.
Heure: 60 minutes
| Durée (min) | Description |
|---|---|
| 20 | Problème 1: Mise en œuvre du stylo et du papier d’un pass avant (exemple de la conférence) |
| 20 | Problème 2: Développer un réseau neuronal à partir de zéro en utilisant Numpy (exemple de la conférence) |
| 10 | Problème 3: Développer un réseau de neurones à partir de l’utilisation de Keras (exemple de la conférence avec des poids définis et des poids aléatoires) |
| 10 | Récapitulation du processus de transmission de l’avance |
Tutoriel 2 — Dérivation et application de la rétropropagation
Instructions de l’enseignant
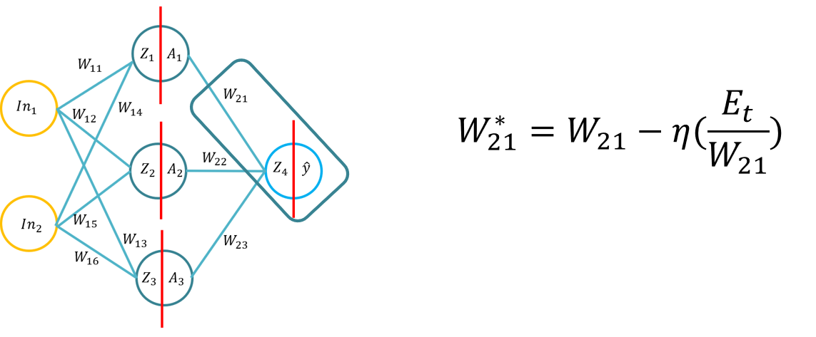
- Ce tutoriel présentera aux étudiants les fondamentaux de l’algorithme d’apprentissage de rétropropagation pour un réseau de neurones artificiels. Ce tutoriel consistera en la dérivation de l’algorithme de rétropropagation à l’aide de stylo et de papier, puis l’application de l’algorithme de rétropropagation pour trois fonctions différentes d’activation de couches cachées (Sigmoid, Tan H et ReLu), en utilisant Python avec uniquement la bibliothèque Numpy (pour la manipulation des matrices) et ensuite en utilisant KERAS. Cela s’appuiera sur la compréhension fondamentale des fonctions d’activation variables lorsqu’un réseau neuronal apprend et comment les fonctions d’activation diffèrent dans la complexité informatique et l’application du stylo et du papier, pour coder à partir de zéro en utilisant Numpy, puis en utilisant un module de haut niveau -> Keras.
- Note: La topologie est la même que la Conférence 1/Tutorial 1, mais les poids et les entrées sont différents, vous pouvez bien sûr utiliser les mêmes poids.
- Les étudiants seront confrontés à quatre problèmes (le premier étant facultatif ou en tant que matériel supplémentaire):
- Problème 1: La dérivation de l’algorithme de rétropropagation (en utilisant la fonction Sigmoid pour les fonctions d’activation interne et externe et MSE comme fonction de perte), les étudiants seront invités à dériver la formule de rétropropagation (20 minutes à compléter).
- Problème 2: Les étudiants appliqueront trois fonctions d’activation pour une seule mise à jour du poids (backpropagation SGD), en utilisant le stylo et le papier pour (20 minutes):
- Sigmoïde (couche cachée), Sigmoid (couche extérieure) et MSE
- Tan H (couche cachée), Sigmoid (couche extérieure) et MSE
- ReLU (Couche cachée), Sigmoid (Couche extérieure) et MSE
- Problème 3: Les étudiants seront invités (avec des conseils en fonction de l’expérience de codage précédente) à développer un réseau neuronal à partir de zéro en utilisant uniquement le module Numpy, et les poids et les fonctions d’activation où l’option de choisir parmi une fonction d’activation de couche cachée est fournie pour mettre à jour les poids à l’aide de SGD (20 minutes à compléter).
- Problème 4: Les étudiants seront invités (avec des conseils en fonction de l’expérience de codage préalable) à développer un réseau neuronal en utilisant le module Tensorflow 2.X avec le module inbuild Keras, et les poids et les fonctions d’activation, puis en utilisant des poids aléatoires pour compléter une ou plusieurs mises à jour de poids. S’il vous plaît pas que Keras utilise une légère perte MSE différente, la perte diminue plus rapidement dans l’exemple Keras.
- Keras MSE = perte = carré(y_true — y_pred)
- Tutoriel MSE = perte = (carré(y_true — y_pred))*0.5
- Les sous-objectifs de ces trois problèmes, c’est d’amener les élèves à comprendre l’algorithme de rétropropagation, de l’appliquer afin que pour le réglage hypermétrique, les élèves soient en mesure de mieux comprendre les effets d’hyperparamètre.
Heure: 60 minutes
| Durée (min) | Description |
|---|---|
| 20 (facultatif) | Problème 1: calcul de la formule de rétropropagation en utilisant la fonction Sigmoid pour les fonctions d’activation interne et externe et MSE comme fonction de perte (facultatif) |
| 20 | Problème 2: Les étudiants appliqueront trois fonctions d’activation pour une seule mise à jour du poids (backpropagation SGD), en utilisant le stylo et le papier pour (20 minutes): |
| 20 | Problème 3: Les étudiants développeront un réseau neuronal à partir de zéro en utilisant uniquement le module Numpy, où l’utilisateur peut sélectionner parmi l’une des trois fonctions d’activation de couches cachées où le code peut préformer la rétropropagation. |
| 10 | Problème 4: Les étudiants utiliseront le module Tensorflow 2.X avec le module Keras inbuild, préformer la rétropropagation à l’aide de SGD. |
| 10 | Récapitulation du processus de transmission de l’avance |
Tutoriel 3 — Tuning Hyperparamètre
Instructions de l’enseignant

- Ce tutoriel présentera aux étudiants les principes fondamentaux de l’hyperparamètre pour un réseau de neurones artificiels. Ce tutoriel consistera à suivre plusieurs hyperparamètres puis à évaluer en utilisant les mêmes configurations de modèles que la conférence (Lecture 3). Ce tutoriel se concentrera sur la modification systématique des hyperparamètres et l’évaluation des parcelles diagnostiques (en utilisant la perte — mais cela pourrait être facilement modifié pour l’exactitude car il s’agit d’un problème de classification) à l’aide de l’ensemble de données du recensement. À la fin de ce tutoriel (les exemples étape par étape), les étudiants seront censés compléter une pratique avec une évaluation supplémentaire pour l’équité (sur la base de l’évaluation de la performance sous-ensemble).
- Notes:
- Il y a prétraitement effectué sur l’ensemble de données (inclus dans le bloc-notes), cependant, c’est le minimum pour que l’ensemble de données fonctionne avec le ANN. Ceci n’est pas exhaustif et n’inclut aucune évaluation (biais/équité).
- Nous utiliserons des parcelles diagnostiques pour évaluer l’effet du tunning hyperparamètre et en particulier une focalisation sur la perte, où il convient de noter que le module que nous utilisons pour tracer la perte est matplotlib.pyplot, donc l’axe est mis à l’échelle. Cela peut signifier que des différences significatives peuvent apparaître non significatives ou vice versa lorsque l’on compare la perte des données d’entraînement ou de test.
- Certaines libertés pour l’échafaudage sont présentées, comme l’utilisation d’Epochs d’abord (presque comme technique de régularisation) tout en maintenant la taille du lot constant.
- Pour fournir des exemples clairs (c.-à-d. surajustement), certains ajustements supplémentaires à d’autres hyperparamètres peuvent avoir été inclus pour fournir des tracés diagnostiques clairs pour les exemples.
- Une fois qu’une capacité et une profondeur raisonnables ont été identifiées, cela ainsi que d’autres hyperparamètres sont verrouillés pour suivre les exemples dans la mesure du possible.
- Enfin, certaines cellules peuvent prendre un certain temps à s’entraîner, même avec un accès GPU.
- Les étudiants seront présentés avec plusieurs étapes pour le tutoriel:
- Étape 1: Quelques prétraitements de base pour l’ensemble de données du recensement des adultes
- Étape 2: Capacité et profondeur (y compris les exemples suivants):
- Pas de convergence
- Sous-équipement
- Surajustement
- Convergence
- Étape 3: Époques (en cours et en cours de formation — sans l’introduire comme une technique de régularisation formelle)
- Étape 4: Fonctions d’activation (en ce qui concerne les performances — temps d’entraînement et, dans certains cas, perte)
- Étape 5: Taux d’apprentissage (y compris les exemples suivants):
- SGD Vanille
- SGD avec déclin du taux d’apprentissage
- SGD avec momentum
- Taux d’apprentissage adaptatifs:
- RMSProp
- AdaGrad
- Adam
- Les sous-objectifs de ces cinq parties sont de fournir aux étudiants des exemples et de l’expérience en matière d’hyperparamètres et d’évaluation des effets à l’aide de parcelles diagnostiques.
Heure: 60 minutes
| Durée (min) | Description |
|---|---|
| 5 | Prétraitement des données |
| 10 | Capacité et profondeur de tunning (sous et sur ajustement) |
| 10 | Époques (sous et sur la formation) |
| 10 | Tailles de lots (pour la suppression du bruit) |
| 10 | Fonctions d’activation (et leurs effets sur les performances — temps et précision) |
| 10 | Taux d’apprentissage (vanille, LR Decay, Momentum, Adaptatif) |
| 5 | Récapituler certains hyperparamètres de base (ReLu, Adam) et le tunning d’autres (capacité et profondeur). |
Remerciements
Keith Quille (TU Dublin, campus de Tallaght) http://keithquille.com
Le programme de master IA centré sur l’humain a été cofinancé par le mécanisme pour l’interconnexion en Europe de l’Union européenne dans le cadre de la subvention CEF-TC-2020-1 Digital Skills 2020-EU-IA-0068.