
Adminisztratív információk
| Cím | Oktatóanyag: A mélytanulás alapjai |
| Időtartam | 180 perc (60 perc bemutatónként) |
| Modul | B |
| Lecke típusa | Bemutató |
| Fókusz | Technikai – Mély tanulás |
| Téma | Előre és backpropagation |
Kulcsszó
előreterjedés, backpropagation,hyperparaméter tuning,
Tanulási célok
- a hallgató megérti az előreterjedés fogalmát
- a diákok megtekinthetik, hogyan lehet a backpropagationt
- a diák alkalmazhatja a backpropagation-t
- a tanuló megtanulja a hiperparaméterek hangolásának módját
Várható előkészítés
Az előtt befejezendő tanulási események
Kötelező a diákok számára
- John D Kelleher és Brain McNamee. (2018), A gépi tanulás alapjai a prediktív adatelemzéshez, MIT Press.
- Michael Nielsen vagyok. (2015), Neural Networks and Deep Learning, 1. Eltökélt sajtó, San Francisco CA USA.
- Charu C. Aggarwal vagyok. (2018), Neural Networks and Deep Learning, 1. Springer
- Antonio Gulli, Sujit Pal. Mély tanulás Keras, Packt, [ISBN: 9781787128422].
Választható diákok számára
- Mátrixok szorzata
- Kezdés a Numpy-val
- Lineáris és logisztikai regresszió ismerete
Referenciák és háttér a diákok számára
Egy sem.
Ajánlott tanároknak
Egy sem.
Leckeanyagok
Egy sem.
Utasítások tanároknak
Ez a tanulási esemény három oktatóanyagból áll, amelyek alapvető mélytanulási témákat fednek le. Ez a bemutató sorozat áttekintést nyújt a határidős bérletről, a backpropagation levezetéséről és a kód használatáról, hogy áttekintést nyújtson a hallgatók számára arról, hogy az egyes paraméterek mit tesznek, és hogyan befolyásolhatja a neurális hálózat tanulását és konvergenciáját:
- Előreterjedés: Toll- és papírpéldák, valamint Python-példák a Numpy (alapvető) és a Keras segítségével, amelyek magas szintű modult mutatnak (amely Tensorflow 2.X-et használ).
- A backpropagation levezetése és alkalmazása: Toll- és papírpéldák, valamint Python-példák a Numpy (alapvető) és a Keras segítségével, amelyek magas szintű modult mutatnak (amely Tensorflow 2.X-et használ).
- Hiperparaméter tuning: A Keras példák a konkrét hiperparaméterek megváltoztatásának hatásain alapuló példaértékű diagnosztikai parcellákat emelnek ki (HCAIM példaadatkészlet használata Etikai MI tanításához (Census Dataset).
Kézbesítési jegyzetek (előadások szerint)
- A Sigmoid használata a külső rétegben és az MSE veszteség funkcióként.
- A kapa korlátaival egy egyedi megközelítést/topológiát/problémakörnyezetet választottak ki. Általában egy előremenet regressziójával (az MSE mint veszteségfüggvény) és a backpropagation (így lineáris aktiválási funkcióval a kimeneti rétegben, ahol ez csökkenti a backpropagation függvény származékának összetettségét), akkor jellemzően egy bináris osztályozási függvényre, a kimeneti rétegben lévő szigmoidra és egy bináris cross-entropy veszteségfüggvényre kerülne. Az időkorlátokkal ez az előadás három különböző példa rejtett aktiválási függvényt fog használni, de regressziós problémakörnyezetet fog használni. A kimeneti rétegben a szigmoid aktiválási függvény komplexitásának hozzáadásához, a két első előadásban használt regressziós probléma, a probléma példa a normalizált célértéken alapul (0–1 a 0–100%) százalékos fokozatú probléma alapján, így a szigmoidot aktiváló funkcióként használják a kimeneti rétegben. Ez a megközelítés lehetővé teszi a diákok számára, hogy könnyen migráljanak a regresszió és a bináris osztályozási problémák között, egyszerűen csak a veszteségfüggvény megváltoztatásával, ha bináris osztályozási probléma merül fel, vagy ha nem normalizált regressziós problémát használnak, a hallgató egyszerűen eltávolítja a külső réteg aktiválási funkciót.
- Az alapkomponensek a magas szintű könyvtár, ebben az esetben a KERAS alkalmazása a TensorFlow 2.X könyvtáron keresztül.
- A toll és a papír opcionális, és csak az előrehaladott passz és a backpropagation származékának és alkalmazásának bemutatására használják (az előadási diák példáit használva).
- A Python kódot magas szintű könyvtárak használata nélkül arra használják, hogy megmutassák, milyen egyszerű egy neurális háló (az előadási diák példáit használva). Ez lehetővé teszi a gyors numerikus/mátrix szorzás megvitatását is, és bemutatja, hogy miért használjuk a GPU-kat/TPU-kat opcionális elemként.
- A Keras és a TensorFlow 2.X minden jövőbeli példához használható.
Bemutató 1 – Előreterjedés
Tanári utasítások
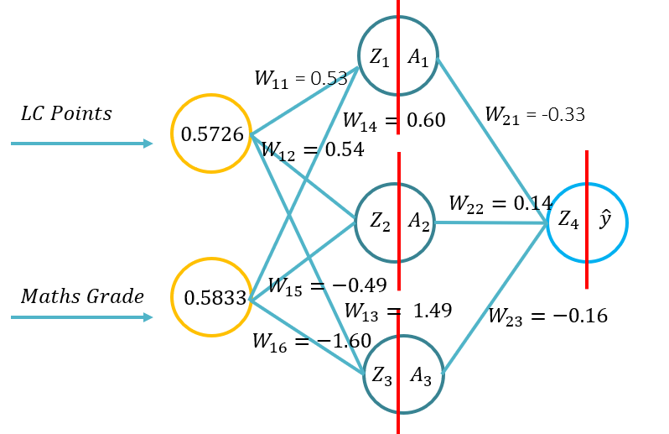
- Ez a bemutató bemutatja a hallgatókat a mesterséges neurális hálózat előreterjedésének alapjaira. Ez a bemutató áll egy előre pass segítségével toll és papír, használata Python csak a Numpy könyvtár (mátrix manipuláció), majd a KERAS.. Ez arra az alapvető megértésre épül, hogy milyen aktiválási függvények vonatkoznak az adott problémakörnyezetre, és hogy az aktiválási funkciók hogyan különböznek a számítási összetettségben és az alkalmazásban a tolltól és a papírtól a kódig a Numpy használatával, majd egy magas szintű modul használatával -> Keras.
- A diákok három problémával szembesülnek:
- Probléma: (Példa az előadásból -> Kép a WIKI RHS-jéről) és kérte, hogy az alábbi paraméterekkel (20 perc kitöltésig) végezzen előre passzt:
- Szigmoid aktiváló funkció a rejtett réteghez
- Szigmoid aktiváló funkció a külső réteg számára
- MSE veszteség funkció
- Probléma: (Példa 1 az előadásból), a hallgatókat felkérik (az előzetes kódolási tapasztalattól függő útmutatással), hogy csak a Numpy modul segítségével fejlesszenek ki egy neurális hálózatot, és az 1. probléma súlyait és aktiválási funkcióit (amelyek megegyeznek az 1. példával az előadásból (20 perc a befejezésig).
- Probléma: (Példa az előadásból, és ugyanazzal a példával, de véletlenszerű súlyokkal), a hallgatókat felkérik (az előzetes kódolási tapasztalattól függő útmutatással), hogy fejlesszenek ki egy neurális hálózatot a Tensorflow 2.X modul használatával az inbuild Keras modullal, valamint az 1. probléma súlyait és aktiválási funkcióit, majd véletlenszerű súlyokat (amelyek megegyeznek az előadás 1. példájával: 20 perc a befejezésig).
- Probléma: (Példa az előadásból -> Kép a WIKI RHS-jéről) és kérte, hogy az alábbi paraméterekkel (20 perc kitöltésig) végezzen előre passzt:
- Ennek a három problémának az alcéljai az, hogy a hallgatók hozzászokjanak az alapvető fogalmak (aktivációs funkciók, topológia és veszteségfüggvények) felépítéséhez és alkalmazásához a mély tanuláshoz.
Idő: 60 perc
| Időtartam (min) | Leírás |
|---|---|
| 20 | Probléma: Toll és papír egy előrehaladott bérlet végrehajtása (példa az előadásból) |
| 20 | Probléma: Neurális hálózat fejlesztése a semmiből Numpy segítségével (példa az előadásból) |
| 10 | Probléma: Neurális hálózat fejlesztése Keras használatával (példa az előadásból, meghatározott súlyokkal és véletlenszerű súlyokkal) |
| 10 | Összefoglaló az előrehaladási folyamatról |
2. bemutató – A backpropagation levezetése és alkalmazása
Tanári utasítások
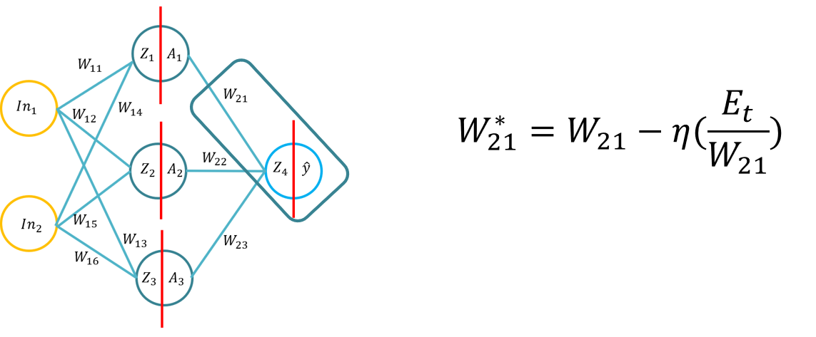
- Ez a bemutató bemutatja a hallgatókat a mesterséges neurális hálózat backpropagation tanulási algoritmusának alapjaihoz. Ez a bemutató áll a derivation a backpropagation algoritmus segítségével toll és papír, majd az alkalmazása a backpropagation algoritmus három különböző rejtett réteg aktiválási funkciók (Sigmoid, Tan H és ReLu), Python csak a Numpy könyvtár (mátrix manipuláció), majd a KERAS.. Ez a változó aktiválási funkciók alapvető megértésére épül, amikor egy neurális hálózat megtanulja, és hogyan különböznek az aktiválási funkciók a számítási összetettségben és az alkalmazásban a tolltól és a papírtól, a kódolás a semmitől a Numpy használatával, majd egy magas szintű modul használatával -> Keras.
- Megjegyzés: A topológia ugyanaz, mint a Lecture 1/Tutorial 1, de a súlyok és bemenetek eltérőek, természetesen ugyanazokat a súlyokat használhatja.
- A hallgatók négy problémával kerülnek bemutatásra (az első opcionális vagy kiegészítő anyagként):
- Probléma: A backpropagation algoritmus (a Sigmoid függvény használata a belső és a külső aktiválási funkciók és az MSE mint veszteség függvény) levezetése a backpropagation formula (a 20 perc befejezéséig).
- Probléma: A diákok három aktiválási funkciót alkalmaznak egyetlen súlyfrissítéshez (SGD backpropagation), toll és papír használatával (20 perc):
- Szigmoid (Rejtett réteg), Sigmoid (külső réteg) és MSE
- Tan H (Rejtett réteg), szigmoid (külső réteg) és MSE
- ReLU (Rejtett réteg), szigmoid (külső réteg) és MSE
- Probléma: A hallgatókat felkérik (az előzetes kódolási tapasztalattól függő útmutatással), hogy csak a Numpy modul használatával fejlesszenek ki egy neurális hálózatot a semmiből, és a súlyokat és az aktiválási funkciókat, ahol az egyetlen rejtett réteg aktiválási funkció közül választhatnak, hogy frissítsék a súlyokat az SGD segítségével (20 perc a befejezésig).
- Probléma: A hallgatók felkérést kapnak (az előzetes kódolási tapasztalattól függően) egy neurális hálózat fejlesztésére a Tensorflow 2.X modul segítségével az inbuild Keras modullal, valamint a súlyok és aktiválási funkciókkal, majd véletlenszerű súlyokkal egy vagy több súlyfrissítés befejezéséhez. Kérjük, ne, mivel a Keras kissé eltérő MSE veszteséget használ, a veszteség gyorsabban csökken a Keras példában.
- Keras MSE = veszteség = négyzet(y_true – y_pred)
- Bemutató MSE = veszteség = (négyzet(y_true – y_pred))*0.5
- Ennek a három problémának az alcéljai az, hogy a diákok megértsék a backpropagation algoritmust, alkalmazzák, hogy a hiperméter tuningnál a diákok jobban megértsék a hiperparaméter hatásait.
Idő: 60 perc
| Időtartam (min) | Leírás |
|---|---|
| 20 (opcionális) | Probléma: a backpropagation formula levezetése a belső és a külső aktiválási funkciók Sigmoid függvényével és az MSE veszteségfüggvényként (opcionális) |
| 20 | Probléma: A diákok három aktiválási funkciót alkalmaznak egyetlen súlyfrissítéshez (SGD backpropagation), toll és papír használatával (20 perc): |
| 20 | Probléma: A diákok egy neurális hálózatot fejlesztenek ki a semmiből, csak a Numpy modul használatával, ahol a felhasználó választhat a három rejtett réteg aktiválási funkció közül, ahol a kód előformálhatja a backpropagation-t |
| 10 | Probléma: A diákok a Tensorflow 2.X modult használják az inbuild Keras modullal, az SGD-vel történő előform backpropagation segítségével. |
| 10 | Összefoglaló az előrehaladási folyamatról |
Bemutató 3 – Hiperparaméter tuning
Tanári utasítások

- Ez a bemutató bemutatja a hallgatókat a mesterséges neurális hálózathoz szükséges hiperparaméter tunning alapjaira. Ez a bemutató több hiperparaméter lezárásából áll, majd kiértékeli ugyanazokat a modelleket, mint az Előadás (3. előadás). Ez a bemutató a hiperparaméterek szisztematikus módosítására és a diagnosztikai parcellák értékelésére összpontosít (veszteség – de ez könnyen módosítható a pontosság érdekében, mivel osztályozási probléma) a népszámlálási adatkészlet segítségével. Ennek a bemutatónak a végén (a lépésről lépésre példák) a hallgatóktól elvárják, hogy egy gyakorlati értékelést végezzenek a méltányosság további értékelésével (a részhalmaz teljesítményértékelése alapján).
- Megjegyzések:
- Az adatkészleten (a jegyzetfüzetben található) előzetes feldolgozás történik, azonban ez a minimum ahhoz, hogy az adatkészlet működjön az ANN-val. Ez nem átfogó, és nem tartalmaz semmilyen értékelést (torzulás/méltányosság).
- Diagnosztikai parcellákat használunk a hiperparaméter tunning hatásának értékelésére, különös tekintettel a veszteségre, ahol meg kell jegyezni, hogy a veszteség ábrázolására használt modul a matplotlib.pyplot, így a tengely skálázódik. Ez azt jelentheti, hogy a jelentős különbségek nem tűnnek jelentősnek, vagy fordítva a képzés vagy a tesztadatok elvesztésének összehasonlításakor.
- Az állványzatra vonatkozó egyes szabadságjogok, mint például az Epochs első használata (majdnem rendezési technikaként), a Batch méretének állandó megtartása mellett.
- Annak érdekében, hogy egyértelmű példákkal szolgáljunk (pl. túlillesztés), előfordulhat, hogy más hiperparaméterekhez további csípéseket is beillesztettek, hogy egyértelmű diagnosztikai táblázatokat adjanak a példákhoz.
- Miután ésszerű kapacitást és mélységet azonosítottak, ezt és más hiperparamétereket is bezárnak, hogy ahol lehetséges, kövessék a példákat.
- Végül néhány cella időbe telik a képzéshez, még GPU hozzáféréssel is.
- A hallgatókat több lépéssel mutatják be a bemutatóhoz:
- 1. lépés: Néhány alapvető előfeldolgozás a Felnőtt népszámlálási adatkészlethez
- 2. lépés: Kapacitás és mélység tunning (beleértve a következő példákat):
- Nincs konvergencia
- Alulkompatibilis
- Túlszereltség
- Konvergencia
- Lépés: Korszakok (képzésen túl és képzés alatt – de nem hivatalos rendezési technikaként vezetik be)
- Lépés: Aktiválási funkciók (a teljesítmény tekintetében – képzési idő és egyes esetekben veszteség)
- 5. lépés: Tanulási arányok (beleértve a következő példákat):
- SGD Vanília
- SGD a tanulási arány romlásával
- SGD lendülettel
- Adaptív tanulási arányok:
- RMSProp
- AdaGrad
- Ádám
- Ennek az öt résznek az alcéljai az, hogy a hallgatóknak példákat és tapasztalatokat biztosítsanak a hiperparaméterek tunningjában és a hatások diagnosztikai parcellák segítségével történő értékelésében.
Idő: 60 perc
| Időtartam (min) | Leírás |
|---|---|
| 5 | Az adatok előzetes feldolgozása |
| 10 | Kapacitás és mélység tunning (alul és felül) |
| 10 | Korszakok (képzés alatt és felett) |
| 10 | Tételméretek (zajcsökkentéshez) |
| 10 | Aktiválási funkciók (és hatásuk a teljesítményre – idő és pontosság) |
| 10 | Tanulási arányok (vanilla, LR Decay, Momentum, Adaptív) |
| 5 | Összefoglalni néhány alapvető hiperparamétert (ReLu, Adam) és mások tunningját (kapacitás és mélység). |
Visszaigazolások
Keith Quille (TU Dublin, Tallaght Campus) http://keithquille.com
A Human-Centered AI Masters programot az Európai Unió Európai Hálózatfinanszírozási Eszköze (CEF-TC-2020–1 Digitális készségek 2020 EU-IA-0068) társfinanszírozta.