
Informações administrativas
| Titulo | Tutorial: Fundamental da aprendizagem profunda |
| Duração | 180 min (60 min por tutorial) |
| Módulo | B |
| Tipo de aula | Tutorial |
| Foco | Técnico — Aprendizagem Aprofundada |
| Tópico | Antecipação e retropropagação |
Palavras-chave
propagação para a frente, retropropagação, afinação do hiperparâmetro,
Objetivos de aprendizagem
- o estudante compreende o conceito de propagação para a frente
- o aluno tem uma visão sobre como derivar a propagação de trás
- o estudante pode candidatar-se à retropropagação
- o aluno aprende o modo de afinar os hiperparâmetros
Preparação prevista
Eventos de aprendizagem a serem concluídos antes
Obrigatório para os Estudantes
- John D. Kelleher e Cérebro McNamee. (2018), Fundamentals of Machine Learning for Predictive Data Analytics, MIT Press.
- Michael Nielsen. (2015), Redes Neurais e Aprendizagem Profunda, 1. Imprensa de determinação, São Francisco CA EUA.
- Charu C. Aggarwal. (2018), Redes Neurais e Aprendizagem Profunda, 1. Springer
- António Gulli, Sujit Pal. Aprendizagem profunda com Keras, Packt, [ISBN: 9781787128422].
Facultativo para Estudantes
- Multiplicação das matrizes
- Começar a usar Numpy
- Conhecimento da regressão linear e logística
Referências e antecedentes para estudantes
Nenhuma.
Recomendado para professores
Nenhuma.
Materiais das aulas
Nenhuma.
Instruções para os professores
Este Evento de Aprendizagem consiste em três conjuntos de tutoriais que abrangem tópicos fundamentais de aprendizagem profunda. Esta série de tutoriais consiste em fornecer uma visão geral de um passe avançado, a derivação da retropropagação e o uso de código para fornecer uma visão geral para os alunos sobre o que cada parâmetro faz, e como isso pode afetar a aprendizagem e convergência de uma rede neural:
- Propagação para a frente: Exemplos de caneta e papel, e exemplos de python que utilizam Numpy (para fundamentos) e Keras que mostram um módulo de alto nível (que utiliza Tensorflow 2.X).
- Derivação e aplicação de retropropagação: Exemplos de caneta e papel, e exemplos de python que utilizam Numpy (para fundamentos) e Keras que mostram um módulo de alto nível (que utiliza Tensorflow 2.X).
- Sintonização hiperparâmetro: Exemplos de Keras que destacam gráficos de diagnóstico exemplares com base nos efeitos da alteração de hiperparametros específicos (utilizando um exemplo de conjunto de dados HCAIM conjuntos de dados para o ensino de IA ética (Census Dataset).
Notas para entrega (de acordo com as palestras)
- Utilização de Sigmoid na camada exterior e MSE como função de perda.
- Com limitações tinas, optou-se por um contexto de abordagem/topologia/problema singular. Normalmente, começar-se-ia com regressão para uma passagem para a frente (com MSE como a função de perda), e para derivar a retropropagação (assim, ter uma função de ativação linear na camada de saída, onde isso reduz a complexidade da derivação da função de retropropagação), então, normalmente, mover-se-ia para uma função de classificação binária, com sigmoide na camada de saída, e uma função binária de perda de entropia cruzada. Com restrições de tempo, este conjunto de palestras usará três diferentes exemplos de funções de ativação oculta, mas usará um contexto de problema de regressão. Para adicionar a complexidade de uma função de ativação sigmoide na camada de saída, o problema de regressão usado nas duas primeiras palestras deste conjunto, o exemplo do problema é baseado em um valor-alvo normalizado (0-1 com base em um problema de grau percentual 0-100 %), assim sigmoide é usado como uma função de ativação na camada de saída. Esta abordagem permite aos alunos migrarem facilmente entre problemas de regressão e classificação binária, simplesmente alterando a função de perda se um problema de classificação binária, ou se um problema de regressão não-normalizado estiver a ser utilizado, o aluno simplesmente remove a função de ativação da camada externa.
- Os componentes principais são a aplicação de, utilizando uma biblioteca de alto nível, neste caso KERAS através da biblioteca TensorFlow 2.X.
- A caneta e o papel são opcionais e só são utilizados para mostrar a derivação e a aplicação do passe e da retropropagação (utilizando os exemplos dos diapositivos das palestras).
- Código Python sem o uso de bibliotecas de alto nível, é usado para mostrar o quão simples uma rede neural (usando os exemplos dos slides de palestra). Isto também permite discutir a multiplicação rápida numérica/matrizes e introduzir por que usamos GPUs/TPUs como um elemento opcional.
- Keras e TensorFlow 2.X são usados e serão usados para todos os exemplos futuros.
Tutorial 1 — Propagação para a frente
Instruções do professor
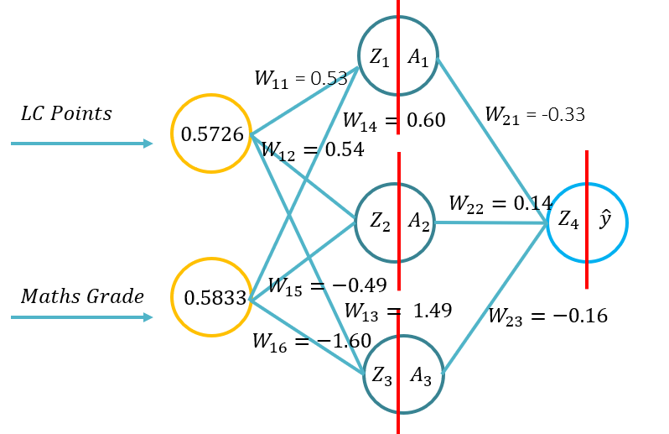
- Este tutorial irá apresentar aos alunos os fundamentos da propagação para a frente para uma rede neural artificial. Este tutorial consistirá num passe para a frente usando caneta e papel, usando Python com apenas a biblioteca Numpy (para manipulação de matrizes) e depois usando o KERAS. Isto irá basear-se na compreensão fundamental do que as funções de ativação se aplicam a contextos de problema específicos e como as funções de ativação diferem na complexidade computacional e na aplicação da caneta e do papel, para codificar a partir do zero usando Numpy e depois usando um módulo de alto nível -> Keras.
- Os alunos serão confrontados com três problemas:
- Problema 1: (Exemplo 1 da palestra -> Imagem sobre o RHS deste WIKI) e pedido para conduzir um passe para a frente usando os seguintes parâmetros (20 minutos para completar):
- Função de ativação sigmoide para a camada oculta
- Função de ativação sigmoide para a camada exterior
- Função de perda de MSE
- Problema 2: (Exemplo 1 da palestra), os alunos serão convidados (com orientação dependendo da experiência de codificação anterior) a desenvolver uma rede neural a partir do zero usando apenas o módulo Numpy, e os pesos e funções de ativação do problema 1 (que são os mesmos que o Exemplo 1 da palestra (20 minutos para concluir).
- Problema 3: (Exemplo 1 da palestra e usando o mesmo exemplo, mas pesos aleatórios), os alunos serão convidados (com orientação dependendo da experiência de codificação anterior) para desenvolver uma rede neural usando o módulo Tensorflow 2.X com o módulo Keras inbuild, e os pesos e funções de ativação do problema 1, e depois usando pesos aleatórios (que são os mesmos que o Exemplo 1 da palestra: 20 minutos a completar).
- Problema 1: (Exemplo 1 da palestra -> Imagem sobre o RHS deste WIKI) e pedido para conduzir um passe para a frente usando os seguintes parâmetros (20 minutos para completar):
- Os subobjetivos para estes três Problemas, é fazer com que os alunos acostumem-se à estrutura e aplicação de conceitos fundamentais (funções de ativação, topologia e funções de perda) para a aprendizagem profunda.
Tempo: 60 minutos
| Duração (Min) | Descrição |
|---|---|
| 20 | Problema 1: Implementação de um passe para a frente (exemplo da palestra) |
| 20 | Problema 2: Desenvolver uma rede neural a partir do zero usando Numpy (exemplo da palestra) |
| 10 | Problema 3: Desenvolver uma rede neural a partir da utilização de Keras (exemplo da palestra com pesos definidos e pesos aleatórios) |
| 10 | Recapitular sobre o processo de passagem para a frente |
Tutorial 2 — Derivação e aplicação da retropropagação
Instruções do professor
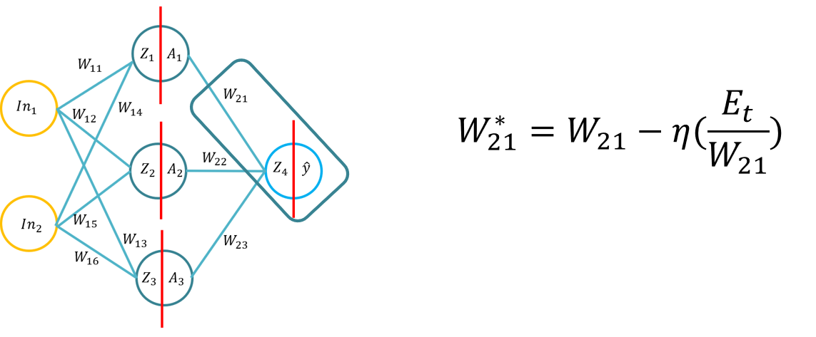
- Este tutorial irá apresentar aos alunos os fundamentos do algoritmo de aprendizagem de retropropagação para uma rede neural artificial. Este tutorial consistirá na derivação do algoritmo de retropropagação utilizando caneta e papel, depois na aplicação do algoritmo de retropropagação para três diferentes funções de ativação de camada oculta (Sigmoid, Tan H e ReLu), utilizando o Python com apenas a biblioteca Numpy (para manipulação de matrizes) e depois utilizando o KERAS. Isto irá basear-se na compreensão fundamental das diferentes funções de ativação quando uma rede neural aprende e como as funções de ativação diferem na complexidade computacional e na aplicação da caneta e do papel, para codificar a partir do zero usando Numpy e depois usando um módulo de alto nível -> Keras.
- Nota: A topologia é a mesma que a Lecture 1/Tutorial 1, mas os pesos e entradas são diferentes, é claro que pode usar os mesmos pesos.
- Os alunos serão apresentados com quatro problemas (o primeiro é opcional ou como material adicional):
- Problema 1: A derivação do algoritmo de retropropagação (utilizando a função Sigmoid para as funções de ativação interior e exterior e MSE como função de perda), os alunos serão convidados a derivar a fórmula de retropropagação (20 minutos para completar).
- Problema 2: Os alunos aplicarão três funções de ativação para uma única atualização de peso (SGD backpropagation), utilizando caneta e papel durante (20 minutos):
- Sigmoide (camada oculta), sigmoide (camada exterior) e MSE
- Tan H (camada oculta), sigmoide (camada exterior) e MSE
- ReLU (camada oculta), sigmoide (camada exterior) e MSE
- Problema 3: Os alunos serão convidados (com orientação dependendo da experiência de codificação anterior) a desenvolver uma rede neural a partir do zero usando apenas o módulo Numpy, e os pesos e funções de ativação onde a opção de selecionar a partir de qualquer uma função de ativação de camada oculta é fornecida para atualizar os pesos usando SGD (20 minutos para concluir).
- Problema 4: Os alunos serão convidados (com orientação de acordo com a experiência de codificação anterior) a desenvolver uma rede neural usando o módulo Tensorflow 2.X com o módulo Keras inbuild, e os pesos e funções de ativação, e depois usando pesos aleatórios para completar uma ou várias atualizações de peso. Por favor, não como Keras usa uma ligeira perda de MSE diferente, a perda reduz-se mais rapidamente no exemplo Keras.
- Keras MSE = perda = quadrado(y_true — y_pred)
- Tutorial MSE = perda = (quadrado(y_true — y_pred))*0,5
- Os subobjetivos para estes três Problemas, é fazer com que os alunos compreendam o algoritmo de retropropagação, aplique-o para que para a afinação do hipermetro, os alunos sejam capazes de compreender melhor os efeitos do hiperparâmetro.
Tempo: 60 minutos
| Duração (Min) | Descrição |
|---|---|
| 20 (opcional) | Problema 1: derivação da fórmula de retropropagação utilizando a função Sigmoid para as funções de ativação interior e exterior e MSE como função de perda (opcional) |
| 20 | Problema 2: Os alunos aplicarão três funções de ativação para uma única atualização de peso (SGD backpropagation), utilizando caneta e papel durante (20 minutos): |
| 20 | Problema 3: Os alunos desenvolverão uma rede neural a partir do zero usando apenas o módulo Numpy, onde o utilizador pode selecionar a partir de qualquer uma das três funções de ativação de camada oculta onde o código pode pré-formar a retropropagação. |
| 10 | Problema 4: Os alunos usarão o módulo Tensorflow 2.X com o módulo Keras inbuild, pré-formar a retropropagação usando SGD. |
| 10 | Recapitular sobre o processo de passagem para a frente |
Tutorial 3 — Afinação do hiperparâmetro
Instruções do professor

- Este tutorial irá apresentar aos alunos os fundamentos da sintonização hiperparâmetro para uma rede neural artificial. Este tutorial consistirá no rasto de múltiplos hiperparâmetros e, em seguida, na avaliação utilizando as mesmas configurações de modelos que a Lecture (Lecture 3). Este tutorial centrar-se-á na modificação sistemática dos hiperparametros e na avaliação das parcelas diagnósticas (utilizando a perda — mas isso poderia ser facilmente modificado para a precisão, uma vez que é um problema de classificação) utilizando o Census Dataset. No final deste tutorial (os exemplos passo a passo) espera-se que os alunos completem um Prático com uma avaliação adicional para a equidade (com base na avaliação de desempenho do subconjunto).
- Notas:
- Há pré-processamento realizado no conjunto de dados (incluído no bloco de notas), no entanto, este é o mínimo para obter o conjunto de dados para trabalhar com a ANN. Isto não é abrangente e não inclui qualquer avaliação (polaridade/justiça).
- Utilizaremos parcelas diagnósticas para avaliar o efeito da afinação do hiperparâmetro e, em particular, um enfoque na perda, onde deve-se notar que o módulo que usamos para traçar a perda é matplotlib.pyplot, portanto o eixo é dimensionado. Isto pode significar que as diferenças significativas podem não parecer significativas ou vice-versa quando se compara a perda dos dados do treino ou do teste.
- Algumas liberdades para andaimes são apresentadas, como o uso de Epochs primeiro (quase como uma técnica de regularização) enquanto mantém o tamanho do lote constante.
- Para fornecer exemplos claros (ou seja, sobremontagem), alguns ajustes adicionais a outros hiperparametros podem ter sido incluídos para fornecer gráficos de diagnóstico claros para exemplos.
- Uma vez identificada uma capacidade e profundidade razoáveis, este, bem como outros hiperparâmetros, são bloqueados para seguir exemplos sempre que possível.
- Finalmente, algumas das células podem demorar algum tempo a treinar, mesmo com acesso à GPU.
- Os alunos serão apresentados com várias etapas para o tutorial:
- Passo 1: Algum pré-processamento básico para o conjunto de dados do Censo Adulto
- Passo 2: Afinação da capacidade e da profundidade (incluindo os seguintes exemplos):
- Ausência de convergência
- Subequipamento
- Sobreadequação
- Convergência
- Passo 3: Épocas (sobre e em formação — sem introduzi-la como uma técnica de regularização formal)
- Passo 4: Funções de ativação (no que diz respeito ao desempenho — tempo de treino e, em alguns casos, perda)
- Passo 5: Taxas de aprendizagem (incluindo os seguintes exemplos):
- SGD Vanilla
- SGD com decadência da taxa de aprendizagem
- SGD com impulso
- Taxas de aprendizagem adaptativa:
- RMSProp
- AdaGrad
- Adão
- Os subobjetivos para estas cinco partes é fornecer aos alunos exemplos e experiência em hiperparametros de afinação e avaliar os efeitos através de gráficos diagnósticos.
Tempo: 60 minutos
| Duração (Min) | Descrição |
|---|---|
| 5 | Pré-tratamento dos dados |
| 10 | Afinação da capacidade e da profundidade (sob e sobremontagem) |
| 10 | Épocas (sob e sobreformação) |
| 10 | Tamanhos dos lotes (para supressão do ruído) |
| 10 | Funções de ativação (e seus efeitos no desempenho — tempo e precisão) |
| 10 | Taxas de aprendizagem (vanilla, LR Decay, Momentum, Adaptive) |
| 5 | Recapitular alguns hiperparâmetros básicos (ReLu, Adam) e afinação de outros (capacidade e profundidade). |
Agradecimentos
Keith Quille (TU Dublin, Tallaght Campus) http://keithquille.com
O programa de mestrado em IA centrado no ser humano foi cofinanciado pelo Mecanismo Interligar a Europa da União Europeia ao abrigo de subvenções CEF-TC-2020-1 Competências Digitais 2020-EU-IA-0068.