
Informații administrative
| Titlu | Tutorial: Fundamentul învățării profunde |
| Durată | 180 min (60 min per tutorial) |
| Modulul | B |
| Tipul lecției | Tutorial |
| Focalizare | Tehnică – Învățare profundă |
| Subiect | Înainte și Backpropagation |
Cuvinte cheie
propagare înainte, contrapropagare, tuning hiperparametru,
Obiective de învățare
- studentul înțelege conceptul de propagare înainte
- studentul obține viziunea cu privire la modul de a obține backpropagation
- studentul poate aplica backpropagation
- studentul învață cum să regleze hiperparametrii
Pregătirea preconizată
Evenimente de învățare care urmează să fie finalizate înainte
Obligatoriu pentru studenți
- John D Kelleher și Brain McNamee. (2018), Fundamentals of Machine Learning for Predictive Data Analytics, MIT Press.
- Michael Nielsen. (2015), Neural Networks and Deep Learning (Rețele neuronale și învățare profundă), 1. Presa de determinare, San Francisco CA SUA.
- Charu C. Aggarwal. (2018), Neural Networks and Deep Learning (Rețele neuronale și învățare profundă), 1. Springer
- Antonio Gulli, Sujit Pal. Deep Learning cu Keras, Packt, [ISBN: 9781787128422].
Opțional pentru studenți
- Multiplicarea matricelor
- Noțiuni de bază cu Numpy
- Cunoașterea regresiei liniare și logistice
Referințe și context pentru studenți
Nici unul.
Recomandat pentru profesori
Nici unul.
Materiale de lecție
Nici unul.
Instrucțiuni pentru profesori
Acest eveniment de învățare constă din trei seturi de tutoriale care acoperă subiecte fundamentale de învățare profundă. Această serie de tutoriale constă în furnizarea unei imagini de ansamblu a unui pas înainte, derivarea backpropagation și utilizarea codului pentru a oferi studenților o imagine de ansamblu asupra a ceea ce face fiecare parametru și modul în care poate afecta învățarea și convergența unei rețele neuronale:
- Propagare înainte: Exemple de stilou și hârtie și exemple de python folosind Numpy (pentru fundamente) și Keras care prezintă un modul de nivel înalt (care utilizează Tensorflow 2.X).
- Derivarea și aplicarea retropropagation: Exemple de stilou și hârtie și exemple de python folosind Numpy (pentru fundamente) și Keras care prezintă un modul de nivel înalt (care utilizează Tensorflow 2.X).
- Reglarea hiperparametrului: Exemplele Keras care evidențiază parcele de diagnosticare exemplare bazate pe efectele modificării hiperparametrilor specifici (folosind un exemplu HCAIM seturi de date pentru predarea IA etice (Census Dataset).
Note pentru livrare (conform prelegerilor)
- Utilizarea Sigmoid în stratul exterior și MSE ca funcție de pierdere.
- În cazul limitărilor dinților, a fost selectată o abordare singulară/topologie/context de problemă. În mod obișnuit, s-ar începe cu regresia pentru o trecere înainte (cu MSE ca funcție de pierdere) și pentru derivarea backpropagation (având astfel o funcție de activare liniară în stratul de ieșire, unde acest lucru reduce complexitatea derivării funcției backpropagation), Apoi s-ar trece de obicei la o funcție de clasificare binară, cu sigmoid în stratul de ieșire și o funcție binară de pierdere a entropiei. Cu constrângeri de timp, acest set de prelegeri va utiliza trei funcții diferite de activare ascunse, dar va utiliza un context de problemă de regresie. Pentru a adăuga complexitatea unei funcții de activare sigmoidă în stratul de ieșire, problema de regresie utilizată în primele două prelegeri ale acestui set, exemplul problemei se bazează pe o valoare țintă normalizată (0-1 bazată pe o problemă de grad procentual 0-100 %), astfel sigmoidul este utilizat ca funcție de activare în stratul de ieșire. Această abordare permite studenților să migreze cu ușurință între regresie și problemele de clasificare binară, prin simpla modificare a funcției de pierdere numai în cazul în care se utilizează o problemă de clasificare binară sau dacă se utilizează o problemă de regresie nenormalizată, studentul pur și simplu elimină funcția de activare a stratului exterior.
- Componentele de bază sunt aplicarea, folosind o bibliotecă de nivel înalt, în acest caz KERAS prin intermediul bibliotecii TensorFlow 2.X.
- Stiloul și hârtia sunt opționale și utilizate numai pentru a arăta derivarea și aplicarea pasului înainte și a backpropagation (folosind exemplele din diapozitivele de curs).
- Codul Python fără utilizarea bibliotecilor de nivel înalt este folosit pentru a arăta cât de simplu este o rețea neuronală (folosind exemplele din diapozitivele de curs). Acest lucru permite, de asemenea, discuții despre multiplicarea numerică/matrice rapidă și introducem motivul pentru care folosim GPU-uri/TPU-uri ca element opțional.
- Keras și TensorFlow 2.X sunt utilizate și vor fi utilizate pentru toate exemplele viitoare.
Tutorial 1 – Înainte de propagare
Instrucțiuni pentru profesori
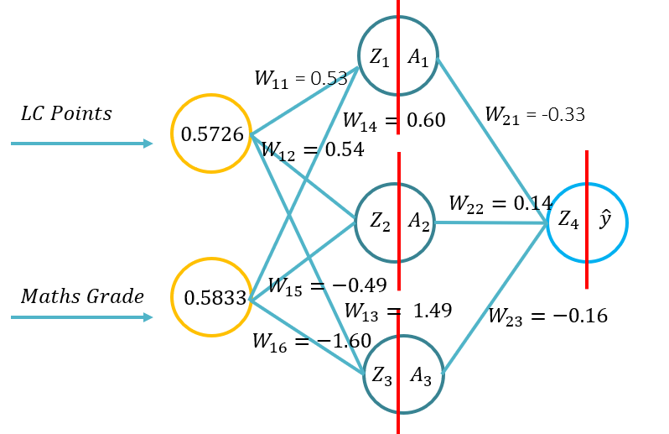
- Acest tutorial va introduce studenții la fundamentele propagării înainte pentru o rețea neuronală artificială. Acest tutorial va consta într-o trecere înainte folosind stilou și hârtie, folosind Python cu doar biblioteca Numpy (pentru manipularea matricelor) și apoi folosind KERAS. Acest lucru se va baza pe înțelegerea fundamentală a funcțiilor de activare care se aplică contextelor de probleme specifice și a modului în care funcțiile de activare diferă în complexitatea computațională și aplicația de la stilou și hârtie, la cod de la zero folosind Numpy și apoi folosind un modul de nivel înalt -> Keras.
- Elevilor li se vor prezenta trei probleme:
- Problema 1: (Exemplu 1 din prelegere -> Imagine pe RHS a acestui WIKI) și a cerut să efectueze o trecere înainte folosind următorii parametri (20 de minute pentru a finaliza):
- Funcția de activare sigmoidă pentru stratul ascuns
- Funcția de activare sigmoidă pentru stratul exterior
- Funcția de pierdere a MSE
- Problema 2: (Exemplul 1 din prelegere), elevilor li se va cere (cu îndrumare în funcție de experiența anterioară de codificare) să dezvolte o rețea neuronală de la zero folosind doar modulul Numpy, precum și greutățile și funcțiile de activare de la problema 1 (care sunt identice cu exemplul 1 din prelegere (20 de minute pentru finalizare).
- Problema 3: (Exemplu 1 din prelegere și folosind același exemplu, dar greutăți aleatorii), elevilor li se va cere (cu îndrumare în funcție de experiența anterioară de codificare) să dezvolte o rețea neuronală folosind modulul Tensorflow 2.X cu modulul Keras inbuild și greutățile și funcțiile de activare de la problema 1, și apoi folosind greutăți aleatorii (care sunt identice cu exemplul 1 din prelegere: 20 de minute până la final).
- Problema 1: (Exemplu 1 din prelegere -> Imagine pe RHS a acestui WIKI) și a cerut să efectueze o trecere înainte folosind următorii parametri (20 de minute pentru a finaliza):
- Subobiectivul acestor trei probleme este de a-i face pe elevi să se obișnuiască cu structura și aplicarea conceptelor fundamentale (funcții de activare, topologie și funcții de pierdere) pentru învățarea profundă.
Ora: 60 de minute
| Durată (min) | Descriere |
|---|---|
| 20 | Problema 1: Punerea în aplicare a unui pas înainte (exemplu din prelegere) |
| 20 | Problema 2: Dezvoltarea unei rețele neuronale de la zero folosind Numpy (exemplu din prelegere) |
| 10 | Problema 3: Dezvoltarea unei rețele neuronale de la utilizarea Keras (exemplu din prelegere cu greutăți stabilite și greutăți aleatorii) |
| 10 | Recapitularea procesului de trecere înainte |
Tutorial 2 – Derivarea și aplicarea backpropagation
Instrucțiuni pentru profesori
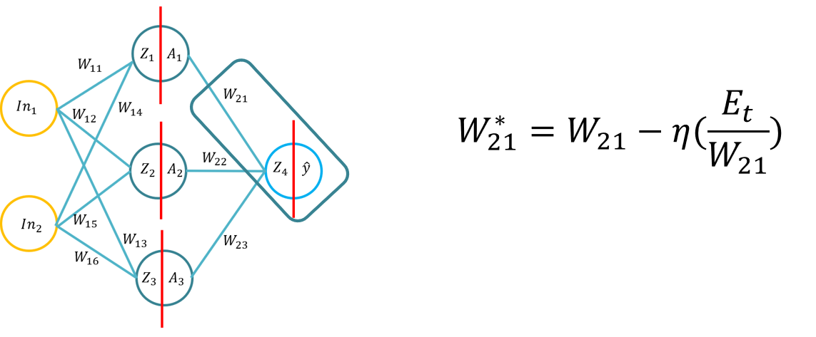
- Acest tutorial va introduce elevii la fundamentele algoritmului de învățare backpropagation pentru o rețea neuronală artificială. Acest tutorial va consta în derivarea algoritmului backpropagation folosind stiloul și hârtia, apoi aplicarea algoritmului backpropagation pentru trei funcții diferite de activare a stratului ascuns (Sigmoid, Tan H și ReLu), folosind Python doar cu biblioteca Numpy (pentru manipularea matricelor) și apoi folosind KERAS. Acest lucru se va baza pe înțelegerea fundamentală a funcțiilor de activare diferite atunci când o rețea neuronală învață și modul în care funcțiile de activare diferă în complexitatea computațională și aplicația de la stilou și hârtie, la cod de la zero folosind Numpy și apoi folosind un modul de nivel înalt -> Keras.
- Notă: Topologia este aceeași cu Lecture 1/Tutorial 1, dar greutățile și intrările sunt diferite, puteți folosi, desigur, aceleași greutăți.
- Elevilor li se vor prezenta patru probleme (prima fiind opțională sau ca material suplimentar):
- Problema 1: Derivarea algoritmului backpropagation (folosind funcția Sigmoid pentru funcțiile de activare interioară și exterioară și MSE ca funcție de pierdere), elevilor li se va cere să obțină formula de backpropagation (20 de minute pentru a finaliza).
- Problema 2: Elevii vor aplica trei funcții de activare pentru o singură actualizare a greutății (SGD backpropagation), folosind stiloul și hârtia pentru (20 de minute):
- Sigmoid (strat ascuns), sigmoid (stratul exterior) și MSE
- Tan H (strat ascuns), sigmoid (stratul exterior) și MSE
- ReLU (strat ascuns), sigmoid (stratul exterior) și MSE
- Problema 3: Elevii vor fi rugați (cu îndrumare în funcție de experiența anterioară de codificare) să dezvolte o rețea neuronală de la zero folosind numai modulul Numpy, iar greutățile și funcțiile de activare în cazul în care opțiunea de a selecta din orice funcție de activare a unui strat ascuns este furnizată pentru a actualiza greutățile folosind SGD (20 de minute pentru a finaliza).
- Problema 4: Elevii vor fi rugați (cu îndrumare în funcție de experiența de codificare anterioară) să dezvolte o rețea neuronală utilizând modulul Tensorflow 2.X cu modulul inbuild Keras și greutățile și funcțiile de activare și apoi folosind greutăți aleatorii pentru a finaliza una sau mai multe actualizări de greutate. Vă rugăm să nu, deoarece Keras utilizează o ușoară pierdere diferită a MSE, pierderea se reduce mai repede în exemplul Keras.
- Keras MSE = pierdere = pătrat(y_true – y_pred)
- Tutorial MSE = pierdere = [pătrat(y_true – y_pred)]*0.5
- Subscopul acestor trei probleme este de a-i face pe elevi să înțeleagă algoritmul de backpropagation, să-l aplice astfel încât, pentru tuningul hipermetrului, elevii să poată înțelege mai bine efectele hiperparametrului.
Ora: 60 de minute
| Durată (min) | Descriere |
|---|---|
| 20 (opțional) | Problema 1: derivarea formulei de backpropagare utilizând funcția Sigmoid pentru funcțiile de activare interioară și exterioară și MSE ca funcție de pierdere (opțional) |
| 20 | Problema 2: Elevii vor aplica trei funcții de activare pentru o singură actualizare a greutății (SGD backpropagation), folosind stiloul și hârtia pentru (20 de minute): |
| 20 | Problema 3: Elevii vor dezvolta o rețea neuronală de la zero folosind doar modulul Numpy, în cazul în care utilizatorul poate selecta din oricare dintre cele trei funcții de activare strat ascuns în cazul în care codul poate preforma backpropagation |
| 10 | Problema 4: Elevii vor utiliza modulul Tensorflow 2.X cu modulul inbuild Keras, preforma backpropagation folosind SGD. |
| 10 | Recapitularea procesului de trecere înainte |
Tutorial 3 – Tuning de hiperparametru
Instrucțiuni pentru profesori

- Acest tutorial va introduce elevii la fundamentele de tunning hiperparametru pentru o rețea neuronală artificială. Acest tutorial va consta în urmărirea mai multor hiperparametri și apoi evaluarea folosind aceleași configurații de modele ca și Lecture (Lectura 3). Acest tutorial se va concentra pe modificarea sistematică a hiperparametrilor și evaluarea parcelelor de diagnosticare (folosind pierderi – dar aceasta ar putea fi ușor modificată pentru acuratețe, deoarece este o problemă de clasificare) utilizând Setul de date privind recensământul. La sfârșitul acestui tutorial (exemplele pas cu pas) elevii vor fi așteptați să completeze o evaluare practică cu o evaluare suplimentară pentru echitate (pe baza evaluării performanței subsetului).
- Note:
- Există preprocesare efectuată pe setul de date (inclus în notebook), cu toate acestea, acesta este minimul pentru ca setul de date să funcționeze cu ANN. Acest lucru nu este cuprinzător și nu include nicio evaluare (părtinire/corectitudine).
- Vom folosi parcele de diagnosticare pentru a evalua efectul de tunning hiperparametru și, în special, un accent pe pierdere, în cazul în care trebuie remarcat faptul că modulul pe care îl folosim pentru a parcela pierderea este matplotlib.pyplot, astfel axa sunt scalate. Acest lucru poate însemna că diferențele semnificative pot să nu apară semnificative sau invers atunci când se compară pierderea datelor de antrenament sau de testare.
- Sunt prezentate unele libertăți pentru schele, cum ar fi utilizarea Epochs în primul rând (aproape ca o tehnică de regularizare), menținând în același timp dimensiunea lotului constantă.
- Pentru a oferi exemple clare (adică supraadaptarea), este posibil să fi fost incluse unele ajustări suplimentare la alți hiperparametri pentru a oferi parcele de diagnosticare clare pentru exemple.
- Odată ce a fost identificată o capacitate rezonabilă și o adâncime rezonabilă, aceasta, precum și alți hiperparametri, sunt blocate pentru a urma exemple, acolo unde este posibil.
- În cele din urmă, unele dintre celule pot dura ceva timp pentru a se antrena, chiar și cu acces GPU.
- Elevii vor fi prezentați cu mai mulți pași pentru tutorial:
- Etapa 1: Unele pre-prelucrări de bază pentru setul de date privind recensământul adulților
- Etapa 2: Capacitatea și adâncimea de reglare (inclusiv următoarele exemple):
- Fără convergență
- Sub-echipare
- Supraadaptare
- Convergență
- Etapa 3: Epoci (de-a lungul și în curs de formare – fără a o introduce ca tehnică formală de regularizare)
- Etapa 4: Funcții de activare (în ceea ce privește performanța – timpul de formare și, în unele cazuri, pierderea)
- Etapa 5: Ratele de învățare (inclusiv următoarele exemple):
- SGD Vanilie
- SGD cu decădere a ratei de învățare
- SGD cu impuls
- Ratele de învățare adaptive:
- RMSProp
- AdaGrad
- Adam
- Subobiectivele pentru aceste cinci părți sunt de a oferi studenților exemple și experiență în tuning hiperparametri și evaluarea efectelor folosind parcele de diagnosticare.
Ora: 60 de minute
| Durată (min) | Descriere |
|---|---|
| 5 | Pre-prelucrarea datelor |
| 10 | Capacitatea și adâncimea de reglare (sub și peste montare) |
| 10 | Epoci (sub și peste formare) |
| 10 | Dimensiuni lot (pentru suprimarea zgomotului) |
| 10 | Funcțiile de activare (și efectele lor asupra performanței – timp și precizie) |
| 10 | Ratele de învățare (vanilla, LR Decay, Momentum, Adaptive) |
| 5 | Recapitulați pe unii hiperparametri de bază (ReLu, Adam) și pe reglarea altora (capacitate și adâncime). |
Confirmări
Keith Quille (TU Dublin, Tallaght Campus) http://keithquille.com
Programul de masterat AI centrat pe om a fost cofinantat de Mecanismul pentru interconectarea Europei al Uniunii Europene sub Grantul CEF-TC-2020-1 Digital Skills 2020-EU-IA-0068.