
Informacje administracyjne
| Tytuł | Poradnik: Podstawa głębokiego uczenia się |
| Czas trwania | 180 min (60 min na samouczek) |
| Moduł | B |
| Rodzaj lekcji | Tutorial |
| Skupienie | Techniczne – głębokie uczenie się |
| Temat | Do przodu i Backpropagation |
Słowa kluczowe
propagacja do przodu, propagacja pleców, strojenie hiperparametrów,
Cele w zakresie uczenia się
- student rozumie koncepcję propagacji do przodu
- student zorientuje się, jak uzyskać wsteczną propagację
- student może zastosować backpropagation
- student uczy się sposobu strojenia hiperparametrów
Oczekiwane przygotowanie
Wydarzenia edukacyjne, które należy ukończyć przed
Obowiązkowe dla studentów
- John D Kelleher i Mózg McNamee. (2018), Podstawy uczenia maszynowego dla Predictive Data Analytics, MIT Press.
- Michael Nielsen. (2015), Sieć neuronowa i głębokie uczenie się, 1. Prasa determinacyjna, San Francisco CA USA.
- Charu C. Aggarwal. (2018), Sieci neuronowe i głębokie uczenie się, 1. Springer
- Antonio Gulli, Sujit Pal. Głębokie uczenie się z Keras, Packt, [ISBN: 9781787128422].
Opcjonalne dla studentów
- Mnożenie matryc
- Zacznij od Numpy
- Znajomość regresji liniowej i logistycznej
Referencje i tło dla studentów
Brak.
Zalecane dla nauczycieli
Brak.
Materiały do lekcji
Brak.
Instrukcje dla nauczycieli
To wydarzenie edukacyjne składa się z trzech zestawów samouczków obejmujących podstawowe tematy głębokiego uczenia się. Ta seria samouczków polega na przedstawieniu przeglądu przepustki do przodu, wyprowadzaniu wstecznej propagacji i wykorzystaniu kodu, aby zapewnić uczniom przegląd tego, co robi każdy parametr i jak może to wpłynąć na uczenie się i konwergencję sieci neuronowej:
- Propagacja do przodu: Przykłady pióra i papieru oraz przykłady pytonowe przy użyciu Numpy (dla podstaw) i Keras pokazujące moduł wysokiego poziomu (który używa Tensorflow 2.X).
- Wyprowadzenie i zastosowanie backpropagacji: Przykłady pióra i papieru oraz przykłady pytonowe przy użyciu Numpy (dla podstaw) i Keras pokazujące moduł wysokiego poziomu (który używa Tensorflow 2.X).
- Strojenie hiperparametrów: Przykłady Keras podkreślające przykładowe wykresy diagnostyczne oparte na efektach zmiany określonych hiperparametrów (przy użyciu przykładowego zestawu danych HCAIM do nauczania etycznej sztucznej inteligencji (zestawdanych spisowych).
Notatki do dostawy (zgodnie z wykładami)
- Zastosowanie Sigmoidu w warstwie zewnętrznej i MSE jako funkcji utraty.
- Z ograniczeniami tine wybrano pojedyncze podejście/topologię/problem kontekst. Zazwyczaj zaczyna się od regresji dla przejścia do przodu (z MSE jako funkcją straty) i do wywoływania wstecznego propagacji (a więc funkcja aktywacji liniowej w warstwie wyjściowej, gdzie zmniejsza to złożoność wyjściowej funkcji propagacji wstecznej), Następnie zazwyczaj przechodzi się do funkcji klasyfikacji binarnej, z sigmoidem w warstwie wyjściowej i binarną funkcją utraty entropii krzyżowej. Z ograniczeniami czasowymi ten zestaw wykładów będzie korzystać z trzech różnych funkcji aktywacji ukrytych przykładów, ale użyje kontekstu problemu regresji. Aby dodać złożoność funkcji aktywacji sigmoidów w warstwie wyjściowej, problem regresji stosowany w dwóch pierwszych wykładach tego zestawu, przykład problemu opiera się na znormalizowanej wartości docelowej (0-1 na podstawie problemu klasy procentowej 0-100 %), więc sigmoid jest używany jako funkcja aktywacji w warstwie wyjściowej. Takie podejście pozwala uczniom łatwo migrować między regresją a problemami klasyfikacji binarnej, po prostu zmieniając funkcję straty tylko wtedy, gdy problem klasyfikacji binarnej lub gdy używany jest nieznormalizowany problem regresji, uczeń po prostu usuwa funkcję aktywacji warstwy zewnętrznej.
- Podstawowe komponenty to aplikacja, przy użyciu biblioteki wysokiego poziomu, w tym przypadku KERAS za pośrednictwem biblioteki TensorFlow 2.X.
- Pióro i papier są opcjonalne i używane tylko do pokazania przepustki do przodu i wstecznej propagacji i aplikacji (przy użyciu przykładów ze slajdów wykładowych).
- Kod Pythona bez użycia bibliotek wysokiego poziomu służy do pokazania, jak prosta jest sieć neuronowa (wykorzystując przykłady ze slajdów wykładowych). Pozwala to również na dyskusję nad szybkim mnożeniem liczb/matryc i wprowadzenie powodów, dla których używamy GPU/TPU jako elementu opcjonalnego.
- Keras i TensorFlow 2.X są używane i będą używane do wszystkich przyszłych przykładów.
Poradnik 1 – Propagacja do przodu
Instrukcje dla nauczycieli
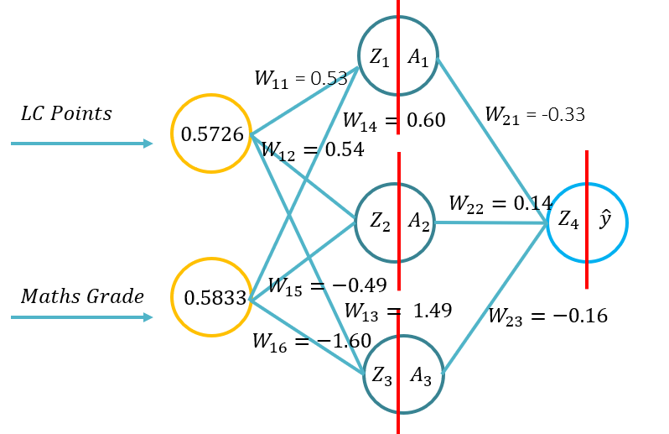
- Ten poradnik wprowadzi studentów do podstaw propagacji do przodu dla sztucznej sieci neuronowej. Ten poradnik będzie składał się z przepustki do przodu za pomocą pióra i papieru, używając Pythona tylko z biblioteki Numpy (do manipulacji matrycami), a następnie za pomocą KERAS.. Będzie to opierać się na podstawowym zrozumieniu, jakie funkcje aktywacji mają zastosowanie do konkretnych kontekstów problemowych i jak funkcje aktywacji różnią się złożonością obliczeniową i aplikacją od pióra i papieru, do kodu od podstaw za pomocą Numpy, a następnie za pomocą modułu wysokiego poziomu -> Keras.
- Uczniowie będą mieli do czynienia z trzema problemami:
- Problem 1: (Przykład 1 z wykładu -> Obraz na RHS tego WIKI) i poprosił o przeprowadzenie przepustki do przodu przy użyciu następujących parametrów (20 minut do ukończenia):
- Funkcja aktywacji sigmoidów dla ukrytej warstwy
- Funkcja aktywacji sigmoidów dla warstwy zewnętrznej
- Funkcja utraty MSE
- Problem 2: (Przykład 1 z wykładu), uczniowie zostaną poproszeni (ze wskazówkami w zależności od wcześniejszego doświadczenia kodowania) o opracowanie sieci neuronowej od podstaw przy użyciu tylko modułu Numpy, oraz ciężarów i funkcji aktywacji z problemu 1 (które są takie same jak Przykład 1 z wykładu (20 minut do ukończenia).
- Problem 3: (Przykład 1 z wykładu i korzystając z tego samego przykładu, ale losowe wagi), uczniowie zostaną poproszeni (ze wskazówkami w zależności od wcześniejszego doświadczenia kodowania) o opracowanie sieci neuronowej przy użyciu modułu Tensorflow 2.X z modułem inbuild Keras, a także wagi i funkcje aktywacji z problemu 1, a następnie przy użyciu wag losowych (które są takie same jak Przykład 1 z wykładu: 20 minut do ukończenia).
- Problem 1: (Przykład 1 z wykładu -> Obraz na RHS tego WIKI) i poprosił o przeprowadzenie przepustki do przodu przy użyciu następujących parametrów (20 minut do ukończenia):
- Celem tych trzech problemów jest przyzwyczajenie uczniów do struktury i zastosowania podstawowych pojęć (funkcji aktywacji, topologii i funkcji utraty) do głębokiego uczenia się.
Czas: 60 minut
| Czas trwania (min) | Opis |
|---|---|
| 20 | Problem 1: Długopis i papier implementacja przepustki do przodu (przykład z wykładu) |
| 20 | Problem 2: Rozwój sieci neuronowej od podstaw za pomocą Numpy (przykład z wykładu) |
| 10 | Problem 3: Rozwój sieci neuronowej z wykorzystaniem Keras (przykład z wykładu z ustalonymi wagami i losowymi wagami) |
| 10 | Podsumowanie procesu przejścia do przodu |
Tutorial 2 – Pochodzenie i zastosowanie backpropagation
Instrukcje dla nauczycieli
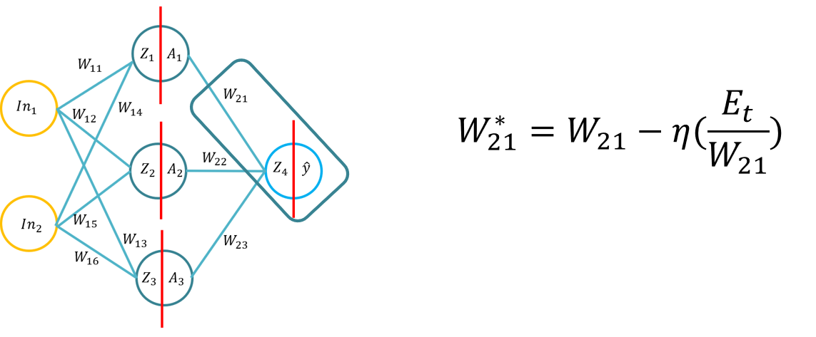
- Ten poradnik wprowadzi studentów do podstaw algorytmu uczenia się backpropagation dla sztucznej sieci neuronowej. Ten poradnik będzie składał się z wyprowadzenia algorytmu backpropagation przy użyciu pióra i papieru, a następnie zastosowania algorytmu backpropagation dla trzech różnych funkcji aktywacji ukrytych warstw (Sigmoid, Tan H i ReLu), używając Pythona tylko z biblioteką Numpy (do manipulacji matrycami), a następnie za pomocą KERAS.. Będzie to opierać się na podstawowym zrozumieniu różnych funkcji aktywacji, gdy sieć neuronowa uczy się i jak funkcje aktywacji różnią się złożonością obliczeniową i aplikacją od pióra i papieru, do kodu od podstaw za pomocą Numpy, a następnie za pomocą modułu wysokiego poziomu -> Keras.
- Uwaga: Topologia jest taka sama jak Wykład 1/Tutorial 1, ale wagi i wejścia są różne, można oczywiście użyć tych samych ciężarów.
- Uczniowie będą mieli cztery problemy (pierwszy jest opcjonalny lub jako dodatkowy materiał):
- Problem 1: Wyprowadzenie algorytmu propagacji wstecznej (przy użyciu funkcji Sigmoid dla wewnętrznych i zewnętrznych funkcji aktywacji oraz MSE jako funkcji straty), uczniowie zostaną poproszeni o wyliczenie formuły propagacji wstecznej (20 minut do ukończenia).
- Problem 2: Studenci będą stosować trzy funkcje aktywacji dla pojedynczej aktualizacji wagi (backpropagation SGD), używając pióra i papieru przez 20 minut:
- Sigmoid (ukryta warstwa), sigmoid (warstwa zewnętrzna) i MSE
- Tan H (ukryta warstwa), sigmoid (warstwa zewnętrzna) i MSE
- ReLU (ukryta warstwa), Sigmoid (warstwa zewnętrzna) i MSE
- Problem 3: Uczniowie zostaną poproszeni (z wytycznymi w zależności od wcześniejszego doświadczenia kodowania) o opracowanie sieci neuronowej od podstaw przy użyciu tylko modułu Numpy, a także wag i funkcji aktywacji, w których dostępna jest opcja wyboru z dowolnej funkcji aktywacji ukrytych warstw, aby zaktualizować wagi za pomocą SGD (20 minut do ukończenia).
- Problem 4: Studenci zostaną poproszeni (ze wskazówkami w zależności od wcześniejszego doświadczenia kodowania) o opracowanie sieci neuronowej przy użyciu modułu Tensorflow 2.X z modułem inbuild Keras oraz wagami i funkcjami aktywacji, a następnie przy użyciu losowych wag do ukończenia jednej lub kilku aktualizacji wagi. Proszę nie, ponieważ Keras wykorzystuje niewielką stratę MSE, strata zmniejsza się szybciej w przykładzie Keras.
- Keras MSE = strata = kwadrat(y_true – y_pred)
- Poradnik MSE = strata = (kwadrat(y_true – y_pred))*0.5
- Celem podrzędnym dla tych trzech problemów jest skłonienie uczniów do zrozumienia algorytmu propagacji wstecznej, zastosowanie go tak, aby do strojenia hipermetrów uczniowie byli w stanie lepiej zrozumieć efekty hiperparametru.
Czas: 60 minut
| Czas trwania (min) | Opis |
|---|---|
| 20 (opcjonalnie) | Problem 1: wyprowadzenie formuły propagacji wstecznej przy użyciu funkcji Sigmoid dla funkcji aktywacji wewnętrznej i zewnętrznej oraz MSE jako funkcji straty (opcjonalnie) |
| 20 | Problem 2: Studenci będą stosować trzy funkcje aktywacji dla pojedynczej aktualizacji wagi (backpropagation SGD), używając pióra i papieru przez 20 minut: |
| 20 | Problem 3: Studenci będą rozwijać sieć neuronową od podstaw przy użyciu tylko modułu Numpy, w którym użytkownik może wybrać jedną z trzech funkcji aktywacji ukrytych warstw, w których kod może preformować wsteczną propagację |
| 10 | Problem 4: Studenci będą korzystać z modułu Tensorflow 2.X z modułem inbuild Keras, preform backpropagation przy użyciu SGD. |
| 10 | Podsumowanie procesu przejścia do przodu |
Tutorial 3 – Dostrajanie hiperparametrów
Instrukcje dla nauczycieli

- Ten poradnik wprowadzi studentów do podstaw hiperparametru strojenia dla sztucznej sieci neuronowej. Ten poradnik będzie składał się z śledzenia wielu hiperparametrów, a następnie oceny przy użyciu tych samych konfiguracji modeli, co wykład (Wykład 3). Ten poradnik skupi się na systematycznej modyfikacji hiperparametrów i ocenie wykresów diagnostycznych (używając strat – ale można to łatwo modyfikować pod kątem dokładności, ponieważ jest to problem klasyfikacji) za pomocą zestawu danych spisu ludności. Pod koniec tego poradnika (przykłady krok po kroku) studenci będą musieli ukończyć praktyczną z dodatkową oceną uczciwości (w oparciu o ocenę wydajności podzbioru).
- Uwagi:
- Na zbiorze danych odbywa się wstępne przetwarzanie (zawarte w notesie), jednak jest to minimum, aby uzyskać zestaw danych do pracy z ANN. Nie jest to wyczerpujące i nie obejmuje żadnej oceny (przestępczość/sprawiedliwość).
- Wykorzystamy wykresy diagnostyczne do oceny efektu strojenia hiperparametru, a w szczególności skupienia się na utracie, gdzie należy zauważyć, że modułem, którego używamy do wykreślenia straty jest matplotlib.pyplot, dzięki czemu oś jest skalowana. Może to oznaczać, że istotne różnice mogą wydawać się nieistotne lub odwrotnie przy porównywaniu utraty danych ze szkolenia lub testów.
- Przedstawiono niektóre swobody rusztowań, takie jak pierwsze użycie Epoch (prawie jako technika regularyzacji) przy zachowaniu stałej wielkości partii.
- Aby podać jasne przykłady (np. nadmierne dopasowanie) mogły zostać włączone pewne dodatkowe poprawki do innych hiperparametrów, aby zapewnić wyraźne wykresy diagnostyczne dla przykładów.
- Po zidentyfikowaniu rozsądnej pojemności i głębokości, zarówno te, jak i inne hiperparametry, są blokowane dla następujących przykładów, o ile to możliwe.
- Wreszcie, niektóre komórki mogą zająć trochę czasu, aby trenować, nawet przy dostępie GPU.
- Uczniowie otrzymają kilka kroków do tutoriala:
- Krok 1: Niektóre podstawowe przetwarzanie wstępne dla zbioru danych spisu osób dorosłych
- Krok 2: Pojemność i głębokość strojenia (w tym następujące przykłady):
- Brak konwergencji
- Niedopasowanie
- Przeciążenie
- Konwergencja
- Krok 3: Epoki (w trakcie i w trakcie treningu – nie wprowadzając go jako formalnej techniki regulowania)
- Krok 4: Funkcje aktywacji (w odniesieniu do wydajności – czas szkolenia, a w niektórych przypadkach utrata)
- Krok 5: Wskaźniki uczenia się (w tym następujące przykłady):
- SGD Vanilla
- SGD ze spadkiem wskaźnika uczenia się
- SGD z rozmachem
- Adaptacyjne wskaźniki uczenia się:
- RMSProp
- AdaGrad
- Adam
- Celem podrzędnym dla tych pięciu części jest dostarczenie studentom przykładów i doświadczenia w strojeniu hiperparametrów i ocenie efektów za pomocą wykresów diagnostycznych.
Czas: 60 minut
| Czas trwania (min) | Opis |
|---|---|
| 5 | Wstępne przetwarzanie danych |
| 10 | Strojenie pojemności i głębokości (pod i nad montażem) |
| 10 | Epoki (pod i nad treningiem) |
| 10 | Wielkość partii (do tłumienia hałasu) |
| 10 | Funkcje aktywacji (i ich wpływ na wydajność – czas i dokładność) |
| 10 | Wskaźniki uczenia się (vanilla, LR Decay, Momentum, Adaptive) |
| 5 | Podsumowanie niektórych podstawowych hiperparametrów (ReLu, Adam) i strojenie innych (pojemność i głębokość). |
Potwierdzenia
Keith Quille (TU Dublin, Tallaght Campus) http://keithquille.com
Program Masters zorientowany na człowieka został współfinansowany przez instrument „Łącząc Europę” Unii Europejskiej w ramach grantu CEF-TC-2020-1 Umiejętności cyfrowe 2020-EU-IA-0068.