
Informazioni amministrative
| Titolo | Tutorial: Fondamentale del deep learning |
| Durata | 180 min (60 min per tutorial) |
| Modulo | B |
| Tipo di lezione | Esercitazione |
| Focus | Tecnico — Apprendimento profondo |
| Argomento | Avanti e indietropropagazione |
Parole chiave
propagazione in avanti, retropropagazione, sintonizzazione dell'iperparametro,
Obiettivi di apprendimento
- lo studente comprende il concetto di propagazione in avanti
- studente ottenere una visione su come ottenere la retropropagazione
- lo studente può applicare la retropropagazione
- lo studente impara il modo di sintonizzare gli iperparametri
Preparazione prevista
Eventi di apprendimento da completare prima
Obbligatorio per gli studenti
- John D. Kelleher e Brain McNamee (2018), Fondamenti dell'apprendimento automatico per l'analisi predittiva dei dati, MIT Press.
- Michael Nielsen. (2015), Reti neurali e apprendimento profondo, 1. Pressa di determinazione, San Francisco CA USA.
- Charu C. Aggarwal. (2018), Reti neurali e apprendimento profondo, 1. Springer
- Antonio Gulli, Sujit Pal. Apprendimento profondo con Keras, Packt, [ISBN: 9781787128422].
Facoltativo per gli studenti
- Moltiplicazione delle matrici
- Iniziare con Numpy
- Conoscenza della regressione lineare e logistica
Referenze e background per gli studenti
Nessuno.
Consigliato per gli insegnanti
Nessuno.
Materiale didattico
Nessuno.
Istruzioni per gli insegnanti
Questo evento di apprendimento è composto da tre serie di tutorial che coprono argomenti fondamentali di apprendimento profondo. Questa serie di tutorial consiste nel fornire una panoramica di un forward pass, la derivazione della backpropagation e l'uso del codice per fornire una panoramica per gli studenti su ciò che fa ogni parametro e come può influenzare l'apprendimento e la convergenza di una rete neurale:
- Propagazione in avanti: Esempi di penna e carta, ed esempi di python utilizzando Numpy (per i fondamentali) e Keras che mostrano un modulo di alto livello (che utilizza Tensorflow 2.X).
- Derivare e applicare la retropropagazione: Esempi di penna e carta, ed esempi di python utilizzando Numpy (per i fondamentali) e Keras che mostrano un modulo di alto livello (che utilizza Tensorflow 2.X).
- Sintonizzazione dell'iperparametro: Esempi di Keras evidenziano diagrammi diagnostici esemplari basati sugli effetti della modifica di specifici iperparametri (utilizzando un esempio HCAIM Dataset set di dati per l'insegnamento dell'IA etica (Census Dataset).
Note per la consegna (secondo le lezioni)
- Uso di Sigmoid nello strato esterno e MSE come funzione di perdita.
- Con le limitazioni della tensione, è stato selezionato un contesto di approccio/topologia/problema singolare. In genere, si inizia con la regressione per un passaggio in avanti (con MSE come funzione di perdita), e per derivare backpropagation (quindi avere una funzione di attivazione lineare nel livello di output, dove questo riduce la complessità della derivazione della funzione backpropagation), quindi si passerebbe tipicamente ad una funzione di classificazione binaria, con sigmoide nel livello di output, e una funzione di perdita di cross-entropia binaria. Con i vincoli di tempo questo insieme di lezioni utilizzerà tre diverse funzioni di attivazione nascosta di esempio, ma utilizzerà un contesto di problema di regressione. Per aggiungere la complessità di una funzione di attivazione sigmoide nel livello di output, il problema di regressione utilizzato nelle due prime lezioni di questo set, l'esempio di problema si basa su un valore target normalizzato (0-1 basato su un problema di grado percentuale 0-100 %), quindi sigmoide viene utilizzato come funzione di attivazione nel livello di output. Questo approccio consente agli studenti di migrare facilmente tra regressione e problemi di classificazione binaria, semplicemente cambiando la funzione di perdita solo se un problema di classificazione binaria, o se viene utilizzato un problema di regressione non normalizzato, lo studente rimuove semplicemente la funzione di attivazione dello strato esterno.
- I componenti principali sono l'applicazione, utilizzando una libreria di alto livello, in questo caso KERAS tramite la libreria TensorFlow 2.X.
- Penna e carta sono facoltative e utilizzate solo per mostrare la derivazione e l'applicazione del passaggio in avanti e della retropropagazione (utilizzando gli esempi delle diapositive della lezione).
- Il codice Python senza l'uso di librerie di alto livello, viene utilizzato per mostrare quanto semplice una rete neurale (utilizzando gli esempi delle diapositive delle lezioni). Ciò consente anche di discutere sulla moltiplicazione numerica/matrice veloce e introdurre il motivo per cui utilizziamo GPU/TPU come elemento opzionale.
- Keras e TensorFlow 2.X sono utilizzati e saranno utilizzati per tutti gli esempi futuri.
Tutorial 1 — Propagazione in avanti
Istruzioni per l'insegnante
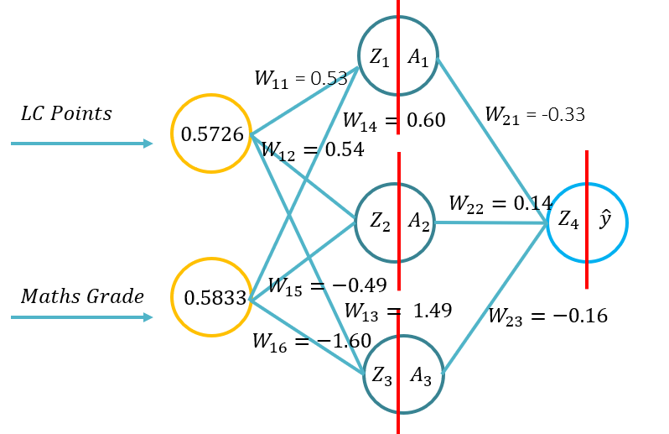
- Questo tutorial introdurrà gli studenti ai fondamenti della propagazione in avanti per una rete neurale artificiale. Questo tutorial consisterà in un passaggio avanti usando penna e carta, usando Python con solo la libreria Numpy (per la manipolazione delle matrici) e quindi usando KERAS.. Questo si baserà sulla comprensione fondamentale di quali funzioni di attivazione si applicano a specifici contesti problematici e di come le funzioni di attivazione differiscono nella complessità computazionale e l'applicazione da penna e carta, per codificare da zero utilizzando Numpy e quindi utilizzando un modulo di alto livello -> Keras.
- Agli studenti saranno presentati tre problemi:
- Problema 1: (Esempio 1 della lezione -> Immagine sul RHS di questo WIKI) e chiesto di condurre un forward pass utilizzando i seguenti parametri (20 minuti per completare):
- Funzione di attivazione sigmoide per il livello nascosto
- Funzione di attivazione sigmoide per lo strato esterno
- Funzione di perdita di MSE
- Problema 2: (Esempio 1 della lezione), agli studenti verrà chiesto (con guida a seconda della precedente esperienza di codifica) di sviluppare una rete neurale da zero utilizzando solo il modulo Numpy, e i pesi e le funzioni di attivazione dal problema 1 (che sono gli stessi dell'esempio 1 della lezione (20 minuti per completare).
- Problema 3: (Esempio 1 della lezione e utilizzando lo stesso esempio ma pesi casuali), agli studenti verrà chiesto (con guida a seconda dell'esperienza di codifica precedente) di sviluppare una rete neurale utilizzando il modulo Tensorflow 2.X con il modulo Keras inbuild, e i pesi e le funzioni di attivazione dal problema 1, e quindi utilizzando pesi casuali (che sono gli stessi dell'esempio 1 della lezione: 20 minuti per completare).
- Problema 1: (Esempio 1 della lezione -> Immagine sul RHS di questo WIKI) e chiesto di condurre un forward pass utilizzando i seguenti parametri (20 minuti per completare):
- Il sottoobiettivo di questi tre Problemi, è quello di far abituare gli studenti alla struttura e all'applicazione di concetti fondamentali (funzioni di attivazione, topologia e funzioni di perdita) per l'apprendimento profondo.
Tempo: 60 minuti
| Durata (min) | Descrizione |
|---|---|
| 20 | Problema 1: Applicazione penna e carta di un forward pass (esempio dalla lezione) |
| 20 | Problema 2: Sviluppo di una rete neurale da zero utilizzando Numpy (esempio dalla lezione) |
| 10 | Problema 3: Sviluppo di una rete neurale dall'utilizzo di Keras (esempio dalla lezione con pesi impostati e pesi casuali) |
| 10 | Riepilogo sul processo forward pass |
Tutorial 2 — Derivazione e applicazione della retropropagazione
Istruzioni per l'insegnante
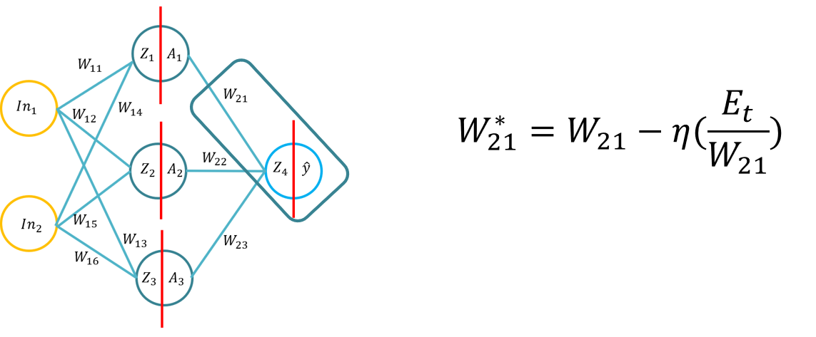
- Questo tutorial introdurrà gli studenti ai fondamenti dell'algoritmo di apprendimento backpropagation per una rete neurale artificiale. Questo tutorial consisterà nella derivazione dell'algoritmo backpropagation utilizzando penna e carta, quindi l'applicazione dell'algoritmo di backpropagation per tre diverse funzioni di attivazione dei livelli nascosti (Sigmoid, Tan H e ReLu), utilizzando Python con solo la libreria Numpy (per la manipolazione delle matrici) e quindi utilizzando KERAS.. Questo si baserà sulla comprensione fondamentale delle varie funzioni di attivazione quando una rete neurale impara e come le funzioni di attivazione differiscono nella complessità computazionale e nell'applicazione da penna e carta, per codificare da zero usando Numpy e quindi utilizzando un modulo di alto livello -> Keras.
- Nota: La topologia è la stessa della lezione 1/Tutorial 1, ma i pesi e gli input sono diversi, è naturalmente possibile utilizzare gli stessi pesi.
- Gli studenti saranno presentati con quattro problemi (il primo è facoltativo o come materiale aggiuntivo):
- Problema 1: La derivazione dell'algoritmo di backpropagation (utilizzando la funzione Sigmoid per le funzioni di attivazione interna ed esterna e MSE come funzione di perdita), agli studenti verrà chiesto di ricavare la formula di retropropagazione (20 minuti per completare).
- Problema 2: Gli studenti applicheranno tre funzioni di attivazione per un singolo aggiornamento del peso (SGD backpropagation), utilizzando penna e carta per (20 minuti):
- Sigmoid (strato nascosto), Sigmoid (strato esterno) e MSE
- Tan H (strato nascosto), Sigmoid (strato esterno) e MSE
- ReLU (strato nascosto), Sigmoid (strato esterno) e MSE
- Problema 3: Agli studenti verrà chiesto (con una guida a seconda dell'esperienza di codifica precedente) di sviluppare una rete neurale da zero utilizzando solo il modulo Numpy, e i pesi e le funzioni di attivazione in cui è fornita l'opzione di selezionare da qualsiasi funzione di attivazione di un livello nascosto per aggiornare i pesi utilizzando SGD (20 minuti per completare).
- Problema 4: Agli studenti verrà chiesto (con una guida a seconda dell'esperienza di codifica precedente) di sviluppare una rete neurale utilizzando il modulo Tensorflow 2.X con il modulo Keras inbuild, i pesi e le funzioni di attivazione e quindi utilizzando pesi casuali per completare uno o più aggiornamenti di peso. Si prega di non poiché Keras utilizza una lieve perdita di MSE diversa, la perdita si riduce più rapidamente nell'esempio di Keras.
- Keras MSE = perdita = quadrato(y_true — y_pred)
- Tutorial MSE = perdita = (quadrato(y_true — y_pred))*0.5
- Il sottoobiettivo per questi tre Problemi, è quello di convincere gli studenti a capire l'algoritmo di backpropagation, applicarlo in modo che per la messa a punto dell'ipermetro, gli studenti saranno in grado di comprendere meglio gli effetti dell'iperparametro.
Tempo: 60 minuti
| Durata (min) | Descrizione |
|---|---|
| 20 (facoltativo) | Problema 1: derivazione della formula backpropagation utilizzando la funzione Sigmoid per le funzioni di attivazione interna ed esterna e MSE come funzione di perdita (Opzionale) |
| 20 | Problema 2: Gli studenti applicheranno tre funzioni di attivazione per un singolo aggiornamento del peso (SGD backpropagation), utilizzando penna e carta per (20 minuti): |
| 20 | Problema 3: Gli studenti svilupperanno una rete neurale da zero utilizzando solo il modulo Numpy, dove l'utente può selezionare da una delle tre funzioni di attivazione dei livelli nascosti in cui il codice può preformare la backpropagation |
| 10 | Problema 4: Gli studenti utilizzeranno il modulo Tensorflow 2.X con il modulo Keras inbuild, preformando la retropropagazione utilizzando SGD. |
| 10 | Riepilogo sul processo forward pass |
Tutorial 3 — Tuning iperparametrico
Istruzioni per l'insegnante

- Questo tutorial introdurrà gli studenti ai fondamenti dell'iperparametro tunning per una rete neurale artificiale. Questo tutorial consisterà nel trailing di più iperparametri e poi nella valutazione utilizzando le stesse configurazioni dei modelli della Lecture (Lecture 3). Questo tutorial si concentrerà sulla modifica sistematica degli iperparametri e sulla valutazione dei grafici diagnostici (utilizzando la perdita — ma questo potrebbe essere facilmente modificato per l'accuratezza in quanto si tratta di un problema di classificazione) utilizzando il Dataset Census. Alla fine di questo tutorial (l'esempio passo dopo passo) gli studenti saranno tenuti a completare una pratica con una valutazione aggiuntiva per l'equità (basata sulla valutazione delle prestazioni dei sottogruppi).
- Note:
- C'è preelaborazione condotta sul set di dati (incluso nel notebook), tuttavia, questo è il minimo per ottenere che il set di dati funzioni con l'ANN. Questo non è completo e non include alcuna valutazione (verità/equità).
- Utilizzeremo diagrammi diagnostici per valutare l'effetto dell'iperparametro tunning e in particolare un focus sulla perdita, dove va notato che il modulo che usiamo per tracciare la perdita è matplotlib.pyplot, quindi l'asse viene scalato. Ciò può significare che le differenze significative possono apparire non significative o viceversa quando si confronta la perdita dei dati di allenamento o di prova.
- Vengono presentate alcune libertà per i ponteggi, come l'uso di Epochs prima (quasi come tecnica di regolarizzazione) mantenendo costante la dimensione del Batch.
- Per fornire esempi chiari (ad esempio overfitting) potrebbero essere stati inclusi alcuni ritocchi aggiuntivi ad altri iperparametri per fornire grafici diagnostici chiari per esempi.
- Una volta identificata una capacità e una profondità ragionevoli, questo e altri iperparametri sono bloccati per seguire esempi ove possibile.
- Infine, alcune celle possono richiedere del tempo per allenarsi, anche con l'accesso alla GPU.
- Gli studenti saranno presentati con diversi passaggi per il tutorial:
- Fase 1: Alcuni pre-elaborazione di base per il set di dati del censimento degli adulti
- Fase 2: Regolazione della capacità e della profondità (compresi i seguenti esempi):
- Nessuna convergenza
- Sottofitting
- Sovrapposizione
- Convergenza
- Fase 3: Epoche (oltre e in corso di formazione — pur non introducendola come tecnica di regolarizzazione formale)
- Fase 4: Funzioni di attivazione (rispetto alle prestazioni — tempo di allenamento e in alcuni casi perdita)
- Fase 5: Tassi di apprendimento (compresi i seguenti esempi):
- SGD Vaniglia
- SGD con decadimento del tasso di apprendimento
- SGD con slancio
- Tassi di apprendimento adattivo:
- RMSProp
- AdaGrad
- Adamo
- Il sottoobiettivo di queste cinque parti è quello di fornire agli studenti esempi ed esperienza nel sintonizzare gli iperparametri e valutare gli effetti utilizzando grafici diagnostici.
Tempo: 60 minuti
| Durata (min) | Descrizione |
|---|---|
| 5 | Pre-trattamento dei dati |
| 10 | Regolazione della capacità e della profondità (sotto e sopra il montaggio) |
| 10 | Epoche (sotto e oltre l'allenamento) |
| 10 | Dimensioni dei lotti (per la soppressione del rumore) |
| 10 | Funzioni di attivazione (e i loro effetti sulle prestazioni — tempo e precisione) |
| 10 | Tassi di apprendimento (vaniglia, LR Decay, Momentum, Adaptive) |
| 5 | Ricapitolare su alcuni iperparametri di base (ReLu, Adam) e il tunning di altri (capacità e profondità). |
Riconoscimenti
Keith Quille (TU Dublino, Tallaght Campus) http://keithquille.com
Il programma Human-Centered AI Masters è stato co-finanziato dal meccanismo per collegare l'Europa dell'Unione europea nell'ambito della sovvenzione CEF-TC-2020-1 Digital Skills 2020-EU-IA-0068.