
Administrativne informacije
| Naslov | Vodič: Temelj dubokog učenja |
| Trajanje | 180 min (60 min po udžbenik) |
| Modul | B |
| Vrsta lekcija | Udžbenik |
| Fokus | Tehničko – dubinsko učenje |
| Tema | Naprijed i natrag propagacija |
Ključne riječi
naprijed propagacija, backpropagation, Hiperparametar ugađanje,
Ciljevi učenja
- student razumije koncept naprijed propagacije
- student dobiva pregled o tome kako izvesti backpropagation
- student može primijeniti backpropagation
- učenik uči način ugađanja hiperparametara
Očekivana priprema
Edukativni događaji koji će biti završeni prije
Obvezno za studente
- John D Kelleher i Brain McNamee. (2018.), Fundamentals of Machine Learning for Predictive Data Analytics (Osnove strojnog učenja za prediktivnu analizu podataka), MIT Press.
- Michael Nielsen. (2015.), Neuralne mreže i duboko učenje, 1. Resorni tisak, San Francisco CA SAD.
- Charu C. Aggarwal. (2018.), Neuralne mreže i duboko učenje, 1. Springer
- Antonio Gulli, Sujit Pal. Dubinsko učenje s Kerasom, Packtom, [ISBN: 9781787128422].
Neobvezno za studente
- Množenje matrica
- Započnite s Numpyjem
- Poznavanje linearne i logističke regresije
Preporuke i pozadina za studente
Nijedan.
Preporučeno nastavnicima
Nijedan.
Nastavni materijali
Nijedan.
Upute za učitelje
Ovaj događaj za učenje sastoji se od tri skupa tutorijala koji pokrivaju temeljne teme dubokog učenja. Ova serija vodiča sastoji se od pružanja pregleda prolaza naprijed, izvođenja backpropagacije i korištenja koda kako bi se studentima pružio pregled o tome što svaki parametar radi i kako može utjecati na učenje i konvergenciju neuronske mreže:
- Propagiranje prema naprijed: Primjeri olovke i papira te primjeri pitona pomoću Numpyja (za osnove) i Kerasa koji pokazuju modul visoke razine (koji koristi Tensorflow 2.X).
- Izvođenje i primjena backpropagacije: Primjeri olovke i papira te primjeri pitona pomoću Numpyja (za osnove) i Kerasa koji pokazuju modul visoke razine (koji koristi Tensorflow 2.X).
- Ugađanje hiperparametra: Primjeri Kerasa u kojima se ističu primjeri dijagnostičkih zapleta temeljenih na učincima na promjenu određenih hiperparametara (korištenjem HCAIM primjera skupova podataka za podučavanje etičke umjetne inteligencije (Census Dataset).
Bilješke za isporuku (prema predavanjima)
- Primjena Sigmoida u vanjskom sloju i MSE-a kao funkcije gubitka.
- S ograničenjima kosine odabran je jedinstveni pristup/topologija/problem kontekst. Tipično, počet će s regresijom za naprijed prolaz (s MSE kao funkcijom gubitka), a za izvođenje backpropagation (stoga ima linearnu funkciju aktivacije u izlaznom sloju, gdje to smanjuje složenost izvedenosti funkcije backpropagacije), Tada bi se obično prebacio na binarnu klasifikacijsku funkciju, sa sigmoidom u izlaznom sloju, i binarnom funkcijom gubitka križne entropije. S vremenskim ograničenjima ovaj skup predavanja koristit će tri različite primjere skrivenih aktivacijskih funkcija, ali će koristiti kontekst problema regresije. Da bi se u izlaznom sloju dodala složenost funkcije aktivacije sigmoida, regresijski problem korišten u dva prva predavanja ovog skupa, primjer problematike temelji se na normaliziranoj ciljnoj vrijednosti (0 – 1 na temelju postotnog razreda problema 0 – 100 %), čime se sigmoid koristi kao aktivacijska funkcija u izlaznom sloju. Ovaj pristup omogućuje studentima da lako migriraju između regresije i binarnih klasifikacijskih problema, jednostavno mijenjajući funkciju gubitka samo ako je binarni klasifikacijski problem ili ako se koristi nenormalizirani regresijski problem, student jednostavno uklanja funkciju aktivacije vanjskog sloja.
- Osnovne komponente su primjena, koristeći biblioteku visoke razine, u ovom slučaju KERAS putem TensorFlow 2.X biblioteke.
- Olovka i papir su neobavezni i koriste se samo za prikazivanje naprijed i backpropagation derivacije i primjene (koristeći primjere iz slajdova predavanja).
- Python kod bez korištenja biblioteka visoke razine koristi se kako bi se pokazalo koliko je jednostavna neuronska mreža (koristeći primjere iz slajdova predavanja). Time se omogućuje i rasprava o brzom umnožavanju brojčanika/matricesa te se navodi zašto upotrebljavamo GPU-ove/TPU-ove kao neobavezni element.
- Keras i TensorFlow 2.X koriste se i koristit će se za sve buduće primjere.
Udžbenik 1 – Prednja propagacija
Upute za nastavnike
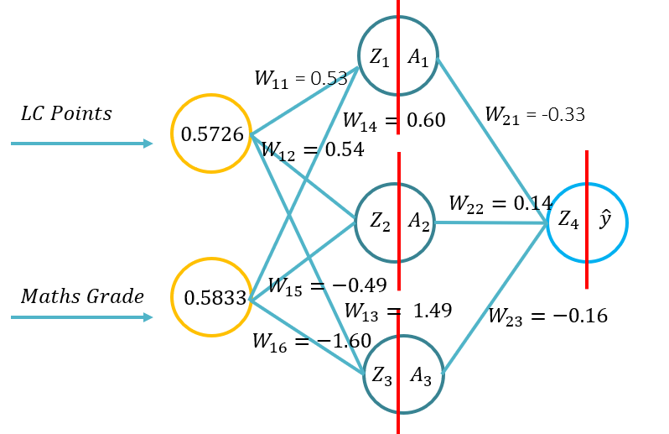
- Ovaj tutorial će upoznati studente s osnovama naprijed propagacije za umjetnu neuronsku mrežu. Ovaj tutorial će se sastojati od naprijed prolaz pomoću olovke i papira, koristeći Python sa samo Numpy biblioteka (za matrice manipulacije), a zatim pomoću KERAS.. To će se temeljiti na temeljnom razumijevanju koje se funkcije aktivacije primjenjuju na specifične problematične kontekste i kako se funkcije aktivacije razlikuju u računalnoj složenosti i primjeni od olovke i papira, do kodiranja od nule pomoću Numpyja i zatim pomoću modula visoke razine -> Keras.
- Učenicima će biti predstavljena tri problema:
- Problem 1.: (Primjer 1 iz predavanja -> Slika o RHS-u ovog WIKI-ja) i zamolili su da provedu propusnicu prema naprijed koristeći sljedeće parametre (20 minuta za dovršetak):
- Funkcija aktivacije sigmoida za skriveni sloj
- Funkcija aktivacije sigmoida za vanjski sloj
- Funkcija gubitka MSE-a
- Drugi problem: (Primjer 1 iz predavanja), studenti će biti zamoljeni (s uputama ovisno o prethodnom iskustvu kodiranja) da razviju neuronsku mrežu od nule koristeći samo Numpy modul, te utege i aktivacijske funkcije iz problema 1 (koje su iste kao primjer 1. iz predavanja (20 minuta do završetka).
- Treći problem: (Primjer 1 iz predavanja i koristeći isti primjer, ali nasumične težine), studenti će biti zamoljeni (uz vodstvo ovisno o prethodnom iskustvu kodiranja) da razviju neuronsku mrežu koristeći Tensorflow 2.X modul s ugrađenim Keras modulom, te utezima i aktivacijskim funkcijama iz problema 1, a zatim pomoću slučajnih težina (koje su iste kao primjer 1. iz predavanja: 20 minuta za dovršetak).
- Problem 1.: (Primjer 1 iz predavanja -> Slika o RHS-u ovog WIKI-ja) i zamolili su da provedu propusnicu prema naprijed koristeći sljedeće parametre (20 minuta za dovršetak):
- Podcilj za ova tri problema je da se učenici naviknu na strukturu i primjenu temeljnih koncepata (funkcije aktivacije, topologije i funkcije gubitka) za duboko učenje.
Vrijeme: 60 minuta
| Trajanje (min) | Opis |
|---|---|
| 20 | Problem 1.: Olovka i papir implementacija naprijed propusnice (primjer iz predavanja) |
| 20 | Drugi problem: Razvoj neuronske mreže od nule pomoću Numpyja (primjer iz predavanja) |
| 10 | Treći problem: Razvoj neuronske mreže pomoću Kerasa (primjer iz predavanja s postavljenim utezima i slučajnim utezima) |
| 10 | Preuzmite proces naprijed prolaza |
Udžbenik 2 – Derivacija i primjena backpropagacije
Upute za nastavnike
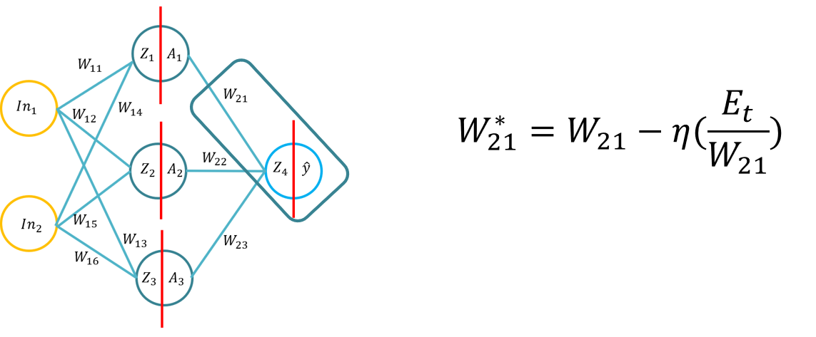
- Ovaj tutorial će upoznati studente s osnovama backpropagation learning algoritam za umjetnu neuronsku mrežu. Ovaj tutorial će se sastojati od izvođenja backpropagation algoritam pomoću olovke i papira, zatim primjena backpropagation algoritam za tri različite funkcije skrivenog sloja aktivacije (Sigmoid, Tan H i ReLu), koristeći Python samo s Numpy bibliotekom (za matrice manipulacije), a zatim pomoću KERAS.. To će se temeljiti na temeljnom razumijevanju različitih aktivacijskih funkcija kada neuronska mreža uči i kako se funkcije aktivacije razlikuju u računalnoj složenosti i primjeni od olovke i papira, do kodiranja od nule pomoću Numpyja, a zatim pomoću modula visoke razine -> Keras.
- Napomena: Topologija je ista kao Predavanje 1/Tutorial 1, ali utezi i ulazi su različiti, naravno možete koristiti iste utege.
- Studenti će biti predstavljeni s četiri problema (prvi je fakultativan ili kao dodatni materijal):
- Problem 1.: Izvođenje algoritma backpropagacije (koristeći funkciju Sigmoid za unutarnje i vanjske aktivacijske funkcije i MSE kao funkciju gubitka), od učenika će se tražiti da izvedu formulu backpropagacije (20 minuta za dovršetak).
- Drugi problem: Studenti će primijeniti tri aktivacijske funkcije za jedno ažuriranje težine (SGD backpropagation), koristeći olovku i papir za (20 minuta):
- Sigmoid (skriveni sloj), sigmoid (vanjski sloj) i MSE
- Tan H (skriveni sloj), sigmoid (vanjski sloj) i MSE
- ReLU (skriveni sloj), sigmoid (vanjski sloj) i MSE
- Treći problem: Učenici će biti zamoljeni (s uputama ovisno o prethodnom iskustvu kodiranja) da razviju neuronsku mrežu od nule koristeći samo Numpy modul, te utege i aktivacijske funkcije gdje je omogućena mogućnost odabira iz bilo koje funkcije aktivacije skrivenih slojeva za ažuriranje utega pomoću SGD-a (20 minuta za dovršetak).
- Četvrti problem: Studenti će biti zamoljeni (uz vodstvo ovisno o prethodnom iskustvu kodiranja) da razviju neuronsku mrežu pomoću Tensorflow 2.X modula s ugrađenim Keras modulom i utezima i aktivacijskim funkcijama, a zatim pomoću slučajnih utega za dovršetak jednog ili više ažuriranja težine. Molimo ne jer Keras koristi blagi gubitak MSE-a, gubitak se brže smanjuje u primjeru Keras.
- Keras MSE = gubitak = kvadrat(y_true – y_pred)
- Udžbenik MSE = gubitak = (kvadrat (y_true – y_pred)) *0.5
- Podcilj za ova tri problema je da učenici razumiju algoritam pozadinske propagacije, primjenjuju ga tako da će za ugađanje hipermetara učenici moći bolje razumjeti učinke hiperparametara.
Vrijeme: 60 minuta
| Trajanje (min) | Opis |
|---|---|
| 20 (neobvezno) | Problem 1.: izvođenje formule za backpropagaciju pomoću funkcije Sigmoid za unutarnje i vanjske aktivacijske funkcije i MSE-a kao funkcije gubitka (neobvezno) |
| 20 | Drugi problem: Studenti će primijeniti tri aktivacijske funkcije za jedno ažuriranje težine (SGD backpropagation), koristeći olovku i papir za (20 minuta): |
| 20 | Treći problem: Studenti će razviti neuronsku mrežu od nule koristeći samo Numpy modul, gdje korisnik može odabrati iz bilo koje od tri funkcije aktivacije skrivenih slojeva gdje kod može pretformirati backpropagation |
| 10 | Četvrti problem: Studenti će koristiti Tensorflow 2.X modul s ugrađenim Keras modulom, preoblikovati backpropagation pomoću SGD-a. |
| 10 | Preuzmite proces naprijed prolaza |
Tutorial 3 – Ugađanje hiperparametra
Upute za nastavnike

- Ovaj će tutorial upoznati studente s osnovama ugađanja hiperparametra za umjetnu neuronsku mrežu. Ovaj tutorial će se sastojati od praćenja više hiperparametara, a zatim evaluacije pomoću istih konfiguracija modela kao Predavanje (predavanje 3). Ovaj će se vodič usredotočiti na sustavnu modifikaciju hiperparametara i procjenu dijagnostičkih parcela (koristeći gubitak – ali to se može lako izmijeniti radi točnosti jer je riječ o klasifikacijskom problemu) pomoću popisa podataka. Na kraju ovog vodiča (primjeri koraka po korak) od studenata će se očekivati da završe praktični s dodatnom evaluacijom za pravednost (na temelju podskupa procjene uspješnosti).
- Napomene:
- Na skupu podataka (uključeno u prijenosno računalo) provodi se prethodna obrada, no to je minimum za rad skupa podataka s ANN-om. To nije sveobuhvatno i ne uključuje evaluaciju (pristranost/pravednost).
- Upotrijebit ćemo dijagnostičke parcele za procjenu učinka ugađanja hiperparametra, a posebno fokus na gubitak, gdje treba napomenuti da je modul koji koristimo za iscrtavanje gubitka matplotlib.pyplot, tako da je os skalirana. To može značiti da se pri usporedbi gubitka podataka o osposobljavanju ili testu mogu činiti znatne razlike ili obratno.
- Predstavljene su neke slobode za skele, kao što je prva uporaba epoha (gotovo kao tehnika regularizacije), dok se veličina serije održava konstantnom.
- Kako bi se pružili jasni primjeri (npr. prenamjena), možda su uključeni neki dodatni ugađači s drugim hiperparametrima kako bi se pružile jasne dijagnostičke parcele za primjere.
- Nakon što se utvrde razumni kapacitet i dubina, ovaj, kao i drugi hiperparametri, zaključani su za sljedeće primjere ako je to moguće.
- Konačno, neke ćelije mogu potrajati neko vrijeme za treniranje, čak i uz GPU pristup.
- Učenici će biti predstavljeni s nekoliko koraka za tutorial:
- Korak 1.: Neke osnovne predobrade za skup podataka popisa odraslih
- Korak 2.: Kapacitet i podešavanje dubine (uključujući sljedeće primjere):
- Nema konvergencije
- Nedovoljna oprema
- Preupravljanje
- Konvergencije
- Treći korak: Epohe (preko i tijekom osposobljavanja – bez uvođenja kao formalne regularizacije)
- Četvrti korak: Aktivacijske funkcije (s obzirom na performanse – vrijeme treninga i u nekim slučajevima gubitak)
- Korak 5.: Stope učenja (uključujući sljedeće primjere):
- SGD Vanilla
- SGD s brzinom učenja propadanja
- SGD sa zamahom
- Prilagodljive stope učenja:
- RMSProp
- AdaGrad
- Adam
- Podcilj za ovih pet dijelova je pružiti studentima primjere i iskustvo u ugađanju hiperparametara i procjeni učinaka pomoću dijagnostičkih parcela.
Vrijeme: 60 minuta
| Trajanje (min) | Opis |
|---|---|
| 5 | Prethodna obrada podataka |
| 10 | Kapacitet i podešavanje dubine (pod i iznad priključka) |
| 10 | Epohe (preko osposobljavanja) |
| 10 | Veličine serije (za suzbijanje buke) |
| 10 | Aktivacijske funkcije (i njihovi učinci na performanse – vrijeme i točnost) |
| 10 | Stope učenja (vanilla, LR Decay, Momentum, Adaptive) |
| 5 | Vratite se na neke osnovne hiperparametre (ReLu, Adam) i podešavanje drugih (kapacitet i dubina). |
Priznanja
Keith Quille (TU Dublin, kampus Tallaght) http://keithquille.com
Diplomski studij umjetne inteligencije usmjeren na čovjeka sufinanciran je Instrumentom za povezivanje Europe Europske unije u okviru bespovratnih sredstava CEF-TC-2020 – 1 Digital Skills 2020-EU-IA-0068.